En este artículo aprenderemos qué es el aprendizaje por refuerzo, lo más novedoso y ambicioso a día de hoy en Inteligencia artificial, veremos cómo funciona, sus casos de uso y haremos un ejercicio práctico completo en Python: una máquina que aprenderá a jugar al pong sóla, sin conocer las reglas ni al entorno.
En este artículo intentaré comentar los seis perfiles más frecuentes solicitados por la industria en la actualidad, sus diversos roles. El artículo esta fuertemente basado en el reporte 2020 de Workera.
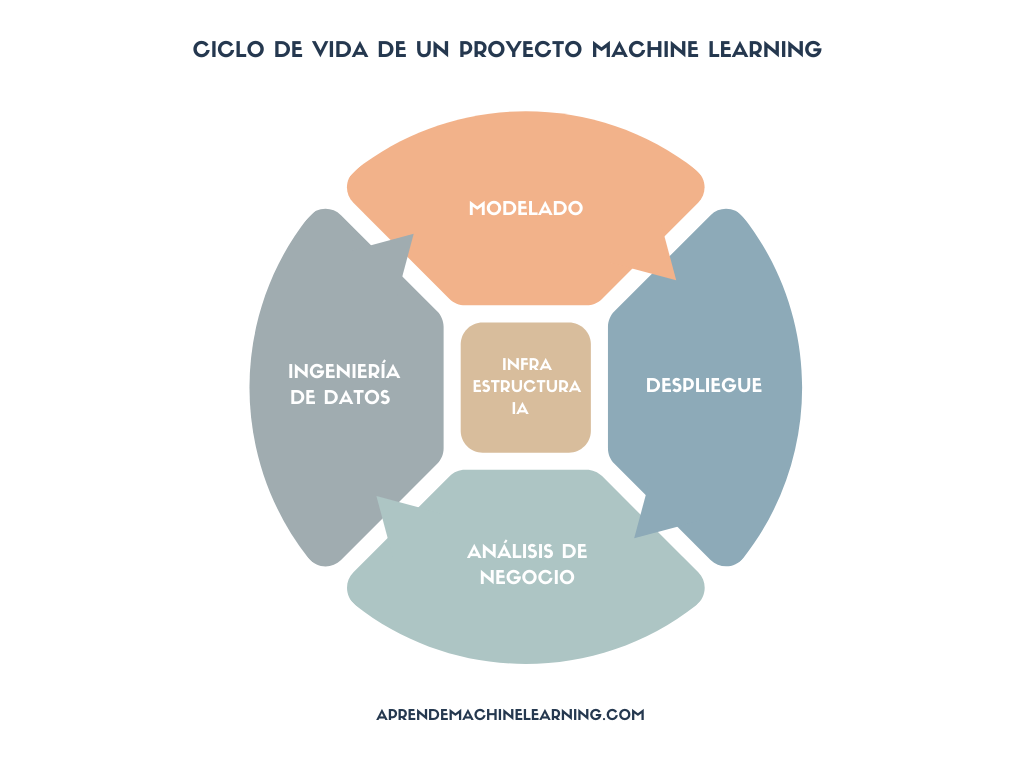
El proyecto de ML
Primero definamos en grandes rasgos las diversas etapas que conforman el desarrollo de un proyecto de Machine Learning.
Primera intuición de detección a partir de la clasificación con CNN
R-CNN: búsqueda selectiva
¿Cómo funciona R-Cnn?
Problemas y mejoras: fast y faster r-cnn
Detección Rápida: YOLO
¿Cómo funciona YOLO?
Arquitectura de la red Darknet
Otras alternativas
2016 – Single Shot Detection
2018 – RetinaNet
2019 – Google Spinet
2020 – Facebook saca del horno DETR
Resumen
Introducción: ¿Qué es la detección de imágenes?
Podemos tener la errónea intuición de que la detección de imágenes sea una tarea sencilla, pero veremos que realmente no lo es y de hecho es un gran problema a resolver. Nosotros los humanos podemos ver una foto y reconocer inmediatamente cualquier objeto que contenga de un vistazo rápido, si hay objetos pequeños o grandes, si la foto es oscura ó hasta algo borrosa. Imaginemos un niño escondido detrás de un árbol donde apenas sobresale un poco su cabeza ó un pie.
Para la detección de imágenes mediante Algoritmos de Machine Learning esto implica una red neuronal convolucional que detecte una cantidad limitada (ó específica) de objetos, no pudiendo detectar objetos que antes no hubiera visto, ó si están en tamaños que logra discernir y todas las dificultades de posibles “focos”, rotación del objeto, sombras y poder determinar en qué posición -dentro de la imagen- se encuentra.
Si es difícil con 1 objeto… imagínate con muchos!.
¿En qué consiste la detección de objetos?
Un algoritmo de Machine Learning de detección, para considerarse como tal deberá:
Detectar multiples objetos.
dar la posición X e Y del objeto en la imagen (o su centro) y dibujar un rectángulo a su alrededor.
Otra alternativa es la segmentación de imágenes (no profundizaremos en este artículo).
Detectar “a tiempo”… o puede que no sirva el resultado. Esta es una característica que debemos tener en cuenta si por ejemplo queremos hacer detección en tiempo real sobre video.
En este nuevo artículo de Aprende Machine Learning explicaremos qué son los outliers y porqué son tan importantes, veremos un ejemplo práctico paso a paso en Python, visualizaciones en 1, 2 y 3 dimensiones y el uso de una librería de propósito general.
Vamos a comentar las diferencias entre los conjuntos de Entrenamiento, Validación y Test utilizados en Machine Learning ya que suele haber bastante confusión en para qué es cada uno y cómo utilizarlos adecuadamente.
Intentaré hacerlo mediante un ejemplo práctico por eso de ser didácticos 🙂
Además veremos que tenemos distintas técnicas de hacer la validación del modelo y aplicarlas con Scikit Learn en Python.
Un nuevo Mundo
Al principio de los tiempos, sólo tenemos un conjunto Pangea que contiene todo nuestro dato disponible. Digamos que tenemos un archivo csv con 10.000 registros.
Para entrenar nuestro modelo de Machine Learning y poder saber si está funcionando bien, alguien dijo: Separemos el conjunto de datos inicial en 2: conjunto de entrenamiento (train) y conjunto de Pruebas (test). Por lo general se divide haciendo “80-20”. Y se toman muestras aleatorias -no en secuencia, si no, mezclado.
y_train con las “etiquetas” de los resultados esperados de X_train
X_test con 2.000 registros para test
y_test con las “etiquetas” de los resultados de X_test
Hágase el conjunto de Test
Lo interesante y a destacar de esto es que una vez los separamos en 8.000 registros para entrenar y 2.000 para probar, usaremos sólo esos 8.000 registros para alimentar al modelo al entrenarlo haciendo:
modelo.fit(X_train, y_train)
Luego de entrenar nuestro modelo y habiendo decidido como métrica de negocio el Accuracy (el % de aciertos) obtenemos un 75% sobre el set de entrenamiento (y asumimos que ese porcentaje nos sirve para nuestro objetivo de negocio).
Los 2.000 registros que separamos en X_test aún nunca han pasado por el modelo de ML. ¿Se entiende esto? porque eso es muy importante!!! Cuando usemos el set de test, haremos:
modelo.predict(X_test)
Como verás, no estamos usando fit()!!! sólo pasaremos los datos sin la columna de “y_test” que contiene las etiquetas. Además remarco que estamos haciendo predicción; me refiero a que el modelo NO se está entrenando ni <<incorporando conocimiento>>. El modelo se limita a “ver la entrada y escupir una salida”.
Cuando hacemos el predict() sobre el conjunto de test y obtenemos las predicciones, las podemos comprobar y contrastar con los valores reales almacenados en y_test y hallar así la métrica que usamos. Los resultados que nos puede dar serán:
Si el accuracy en Test es <<cercano>> al de Entrenamiento (dijimos 75%) por ejemplo en este caso si estuviera entre 65 ú 85% quiere decir que nuestro modelo entrenado está generalizando bien y lo podemos dar por bueno (siempre y cuando estemos conformes con las métricas obtenidas).
Si el Accuracy en Test es muy distinto al de Entrenamiento tanto por encima como por debajo, nos da un 99% ó un 25% (lejano al 75%) entonces es un indicador de que nuestro modelo no ha entrenado bien y no nos sirve. De hecho este podría ser un indicador de Overfitting.
Para evaluar mejor el segundo caso, es donde aparece el “conjunto de Validación”.
Veremos de qué se trata este paso inicial tan importante y necesario para comenzar un proyecto de Machine Learning. Aprendamos en qué consiste el EDA y qué técnicas utilizar. Veamos un ejemplo práctico y la manipulación de datos con Python utilizando la librería Pandas para analizar y Visualizar la información en pocos minutos.
Como siempre, podrás descargar todo el código de la Jupyter Notebook desde mi cuenta de Github (que contiene información extra). Y como BONUS encuentra una notebook con las funciones más útiles de Pandas!
¿Qué es el EDA?
Eda es la sigla en inglés para Exploratory Data Analysis y consiste en una de las primeras tareas que tiene que desempeñar el Científico de Datos. Es cuando revisamos por primera vez los datos que nos llegan, por ejemplo un archivo CSV que nos entregan y deberemos intentar comprender “¿de qué se trata?”, vislumbrar posibles patrones y reconociendo distribuciones estadísticas que puedan ser útiles en el futuro.