
Ejercicio Python de Procesamiento del Lenguaje Natural
( ó “¿Qué tiene Casciari en la cabeza?” )

Luego de haber escrito sobre la teoría de iniciación al NLP en el artículo anterior llega la hora de hacer algunos ejercicios prácticos en código Python para adentrarnos en este mundo.
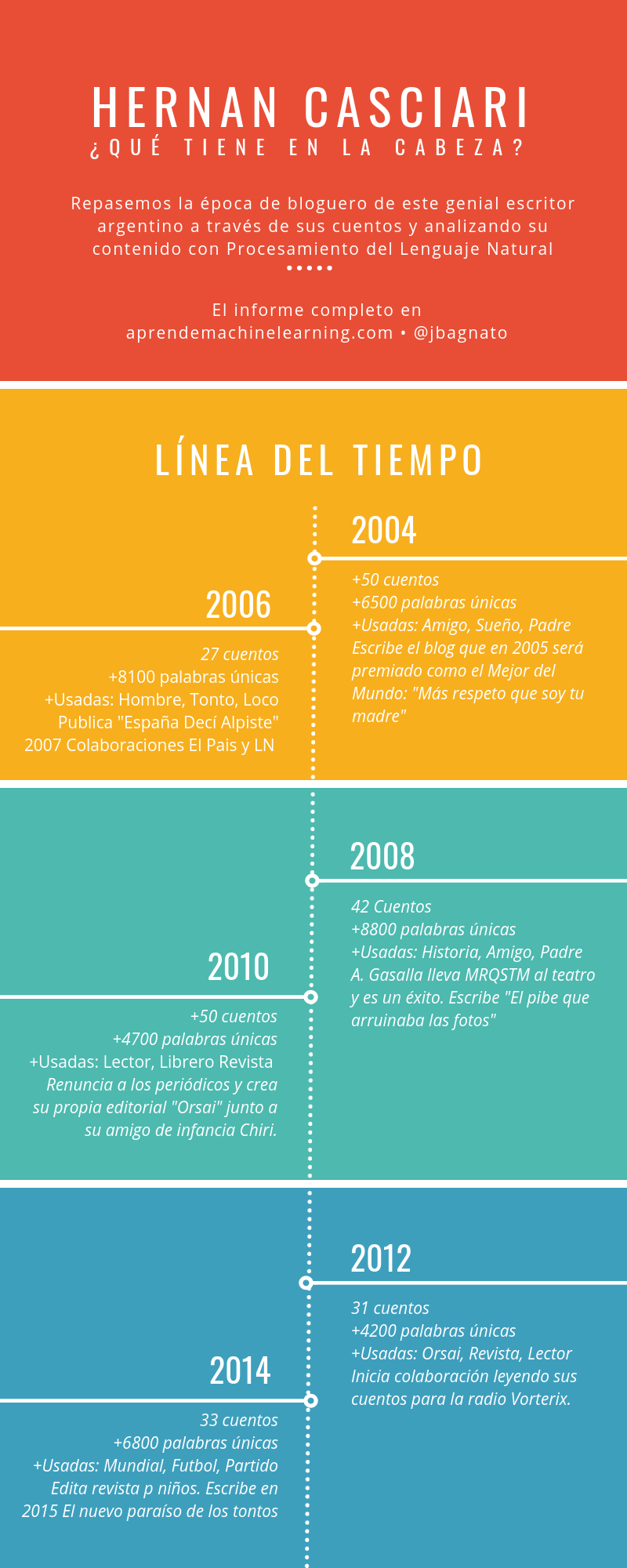
Como la idea es hacer Aprendizaje Automático en Español, se me ocurrió buscar textos en castellano y recordé a Hernan Casciari que tiene los cuentos de su blog disponibles online y me pareció un buen desafío.
Para quien no conozca a Hernan Casciari, es un escritor genial, hace cuentos muy entretenidos, de humor (y drama) muy reales, relacionados con su vida, infancia, relaciones familiares con toques de ficción. Vivió en España durante más de una década y tuvo allí a su primera hija. En 2005 fue premiado como “El mejor blog del mundo” por Deutsche Welle de Alemania. En 2008 Antonio Gasalla tomó su obra “Más respeto que soy tu madre” y la llevó al teatro con muchísimo éxito. Escribió columnas para importantes periódicos de España y Argentina hasta que fundó su propia editorial Orsai en 2010 donde no depende de terceros para comercializar ni distribuir sus productos y siempre ofrece versione en pdf (gratuitos). Tiene 7 libros publicados, apariciones en radio (Vorterix y Perros de la Calle) y hasta llevó sus historias a una genial puesta en escena llamada “Obra en Construcción” que giró por muchas provincias de la Argentina, España y Uruguay.
Agenda del Día: “NLP tradicional”
Lo cierto es que utilizaremos la librería python NLTK para NLP y haremos uso de varias funciones y análisis tradicionales, me refiero a que sin meternos – aún- en Deep Learning (eso lo dejaremos para otro futuro artículo).
- Obtener los Datos (los cuentos)
- Exploración Inicial
- Limpieza de datos
- Análisis Exploratorio
- Análisis de Sentimiento
- Modelado de Tópicos
Vamos al código!
1 – Obtener los Cuentos
Para obtener los textos, haremos webscraping (LEER ARTíCULO) en el blog de Hernan Casciari, recorreremos los cuentos que afortunadamente están clasificados en directorios por año, del 2004 al 2005 y guardaremos todos los posts de cada año en un archivo txt.
ATENCIóN: Este código puede tardar MUCHOS minutos en descargar todos los textos, pues para ser amables con el servidor, haremos un sleep(0.75) entre cada request (y son 386 cuentos).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# Web scraping, pickle imports import requests from bs4 import BeautifulSoup import pickle from time import sleep # Web Scrapes transcript data from blog def url_to_transcript(url): '''Obtener los enlaces del blog de Hernan Casciari.''' page = requests.get(url).text soup = BeautifulSoup(page, "lxml") print('URL',url) enlaces = [] for title in soup.find_all(class_="entry-title"): for a in title.find_all('a', href=True): print("Found link:", a['href']) enlaces.append(a['href']) sleep(0.75) #damos tiempo para que no nos penalice un firewall return enlaces base = 'https://editorialorsai.com/category/epocas/' urls = [] anios = ['2004','2005','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015'] for anio in anios: urls.append(base + anio + "/") print(urls) # Recorrer las URLs y obtener los enlaces enlaces = [url_to_transcript(u) for u in urls] print(enlaces) def url_get_text(url): '''Obtener los textos de los cuentos de Hernan Casciari.''' print('URL',url) text="" try: page = requests.get(url).text soup = BeautifulSoup(page, "lxml") text = [p.text for p in soup.find(class_="entry-content").find_all('p')] except Exception: print('ERROR, puede que un firewall nos bloquea.') return '' sleep(0.75) #damos tiempo para que no nos penalice un firewall return text # Recorrer las URLs y obtener los textos MAX_POR_ANIO = 50 # para no saturar el server textos=[] for i in range(len(anios)): arts = enlaces[i] arts = arts[0:MAX_POR_ANIO] textos.append([url_get_text(u) for u in arts]) print(len(textos)) ## Creamos un directorio y nombramos los archivos por año !mkdir blog for i, c in enumerate(anios): with open("blog/" + c + ".txt", "wb") as file: cad="" for texto in textos[i]: for texto0 in texto: cad=cad + texto0 pickle.dump(cad, file) |
Al finalizar obtendremos una carpeta llamada blog con 12 archivos: 2004.txt a 2015.txt.
Recuerda que puedes descargar todos los archivos, jupyter Notebook y código Python desde mi cuenta de Github
2 – Exploración Inicial / Cargamos los Datos
Cargaremos los archivos txt que creamos en el paso anterior y lo pasaremos a una estructura en un dataframe de Pandas para seguir usando en el próximo paso.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
data = {} for i, c in enumerate(anios): with open("blog/" + c + ".txt", "rb") as file: data[c] = pickle.load(file) # Revisamos que se haya guardado bien print(data.keys()) # Veamos algun trozo de texto print(data['2008'][1000:1222]) # Combine it! data_combined = {key: [value] for (key, value) in data.items()} # We can either keep it in dictionary format or put it into a pandas dataframe import pandas as pd pd.set_option('max_colwidth',150) data_df = pd.DataFrame.from_dict(data_combined).transpose() data_df.columns = ['transcript'] data_df = data_df.sort_index() data_df |

3 – Limpieza de Datos
Ahora aplicaremos algunos de los filtros de limpieza que se suelen usar para poder tratar el texto:
- Pasar texto a minúsculas
- Quitar signos de puntuación (interrogación, etc.)
- Quitar espacios extra, cambio de carro, tabulaciones
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# Apply a first round of text cleaning techniques import re import string def clean_text_round1(text): '''Make text lowercase, remove text in square brackets, remove punctuation and remove words containing numbers.''' text = text.lower() text = re.sub('\[.*?¿\]\%', ' ', text) text = re.sub('[%s]' % re.escape(string.punctuation), ' ', text) text = re.sub('\w*\d\w*', '', text) return text round1 = lambda x: clean_text_round1(x) data_clean = pd.DataFrame(data_df.transcript.apply(round1)) # Apply a second round of cleaning def clean_text_round2(text): '''Get rid of some additional punctuation and non-sensical text that was missed the first time around.''' text = re.sub('[‘’“”…«»]', '', text) text = re.sub('\n', ' ', text) return text round2 = lambda x: clean_text_round2(x) data_clean = pd.DataFrame(data_clean.transcript.apply(round2)) data_clean # Let's pickle it for later use data_df.to_pickle("corpus.pkl") |
Y creamos nuestro “Bag of Words”
A partir del dataset que limpiamos, creamos y contamos las palabras:
(el archivo spanish.txt lo incluye NLTK ó si no lo tienes, copia de mi Github en el mismo directorio en donde tienes el código)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
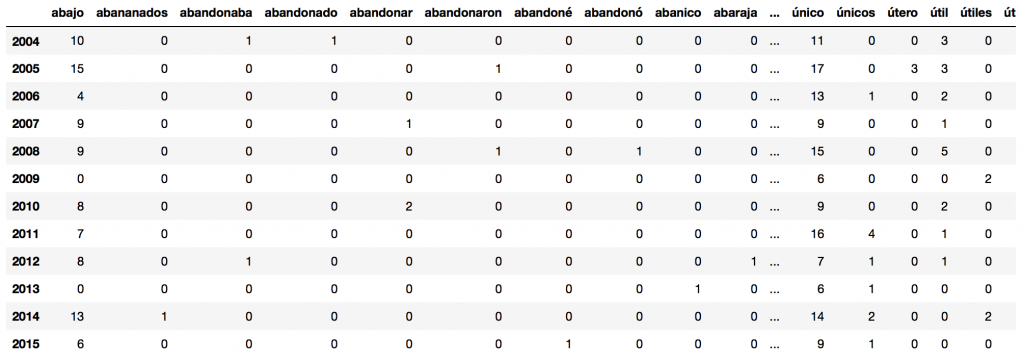
# We are going to create a document-term matrix using CountVectorizer, and exclude common Spanish stop words from sklearn.feature_extraction.text import CountVectorizer with open('spanish.txt') as f: lines = f.read().splitlines() cv = CountVectorizer(stop_words=lines) data_cv = cv.fit_transform(data_clean.transcript) data_dtm = pd.DataFrame(data_cv.toarray(), columns=cv.get_feature_names()) data_dtm.index = data_clean.index data_dtm.to_pickle("dtm.pkl") # Let's also pickle the cleaned data (before we put it in document-term matrix format) and the CountVectorizer object data_clean.to_pickle('data_clean.pkl') pickle.dump(cv, open("cv.pkl", "wb")) data_dtm |
4 – Análisis Exploratorio
Ahora que tenemos nuestro dataset, investigaremos un poco
|
1 2 3 |
data = pd.read_pickle('dtm.pkl') data = data.transpose() data.head() |
4.1 – Palabras más usadas por año
veamos las palabras más usadas cada año:
|
1 2 3 4 5 6 7 8 9 |
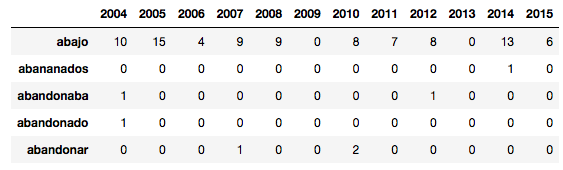
top_dict = {} for c in data.columns: top = data[c].sort_values(ascending=False).head(30) top_dict[c]= list(zip(top.index, top.values)) print(top_dict) # Print the top 15 words by year for anio, top_words in top_dict.items(): print(anio) print(', '.join([word for word, count in top_words[0:14]])) |
|
1 |
--- 2004 si, alex, vez, lucas, cada, dos, ahora, ser, después, casa, años, siempre, nadie, ver <br>--- 2005 si, dos, vez, años, siempre, ser, vida, tiempo, hace, ahora, entonces, mundo, después, dice <br>--- 2006 si, años, dos, vez, siempre, hace, mundo, ser, ahora, entonces, cada, mismo, vida, casa <br>--- 2007 si, siempre, dos, entonces, vez, años, nunca, ahora, sólo, después, mundo, ser, casa, mujer <br>--- 2008 dos, si, años, casa, vez, ahora, después, siempre, entonces, hace, ser, tarde, tiempo, mismo <br>--- 2009 años, si, ahora, casa, vez, después, andrés, ser, dos, vida, hace, mundo, entonces, tres <br>--- 2010 revista, chiri, si, años, orsai, cada, hacer, dos, ahora, ser, hace, vez, casa, lectores <br>--- 2011 orsai, revista, número, lectores, dos, si, vez, chiri, años, ahora, hace, cada, siempre, revistas <br>--- 2012 orsai, dos, cada, si, revista, vez, dijo, chiri, ahora, después, tiempo, mismo, hace, argentina <br>--- 2013 si, dos, años, cada, dijo, papelitos, ve, después, ahora, vez, nunca, tres, tarde, día <br>--- 2014 si, vez, dos, años, después, tres, cada, siempre, casa, ser, lucas, mismo, alex, nunca <br>--- 2015 si, años, casa, hija, dos, entonces, ahora, nunca, después, siempre, vez, dijo, vida, ser <br> |
4.2 Agregamos Stop Words
Vemos en el listado que hay palabras muy usadas pero que realmente no tienen un significado útil para el análisis. Entonces haremos lo siguiente: uniremos las 12 listas de más palabras en un nuevo ranking y de esas, tomaremos las “más usadas” para ser agregar en nuestro listado de Stop Words.
|
1 2 3 4 5 6 7 8 9 10 11 |
from collections import Counter # Let's first pull out the top 30 words for each anio words = [] for anio in data.columns: top = [word for (word, count) in top_dict[anio]] for t in top: words.append(t) print(Counter(words).most_common()) add_stop_words = [word for word, count in Counter(words).most_common() if count > 6] add_stop_words |
|
1 |
['si',<br> 'vez',<br> 'cada',<br> 'dos',<br> 'ahora',<br> 'después',<br> 'años',<br> 'hace',<br> 'casa',<br> 'nunca',<br> 'siempre',<br> 'mundo',<br> 'día',<br> 'mismo',<br> 'hacer',<br> 'tiempo',<br> 'ser',<br> 'vida',<br> 'chiri',<br> 'dijo',<br> 'entonces',<br> 'tres',<br> 'noche'] |
4.3 Actualizamos nuestra Bag of Words
Ahora quitaremos las Stop words de nuestro dataset. Usaremos el listado de spanish.txt, el que generamos recién y uno adicional que hice yo a partir de los resultados obtenidos (ojo… esto les puede parecer arbitrario y en parte lo es!)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from sklearn.feature_extraction import text from sklearn.feature_extraction.text import CountVectorizer # Read in cleaned data data_clean = pd.read_pickle('data_clean.pkl') # Add new stop words with open('spanish.txt') as f: stop_words = f.read().splitlines() for pal in add_stop_words: stop_words.append(pal) more_stop_words=['alex','lucas','andrés','mirta','tres','primer','primera','dos','uno','veces', 'así', 'luego', 'quizá','cosa','cosas','tan','asi','andres','todas','sólo','jesús','pablo','pepe'] for pal in more_stop_words: stop_words.append(pal) # Recreate document-term matrix cv = CountVectorizer(stop_words=stop_words) data_cv = cv.fit_transform(data_clean.transcript) data_stop = pd.DataFrame(data_cv.toarray(), columns=cv.get_feature_names()) data_stop.index = data_clean.index # Pickle it for later use import pickle pickle.dump(cv, open("cv_stop.pkl", "wb")) data_stop.to_pickle("dtm_stop.pkl") |
4.4 Nube de Palabras
Haremos una primer aproximación a “qué tenía Hernan Casciari en su cabeza” entre 2004 y 2015 en sus cuentos usando un modo de visualización llamado WordCloud. Esto puede requerir que debas instalar la librería Wordcloud con Pip ó si tienes instalado Anaconda, desde la interface ó por terminal con conda install -c conda-forge wordcloud
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from wordcloud import WordCloud wc = WordCloud(stopwords=stop_words, background_color="white", colormap="Dark2", max_font_size=150, random_state=42) import matplotlib.pyplot as plt plt.rcParams['figure.figsize'] = [16,12] # Create subplots for each anio for index, anio in enumerate(data.columns): wc.generate(data_clean.transcript[anio]) plt.subplot(4, 3, index+1) plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.title(anios[index]) plt.show() |

4.5 Estadísticas de Palabras por año
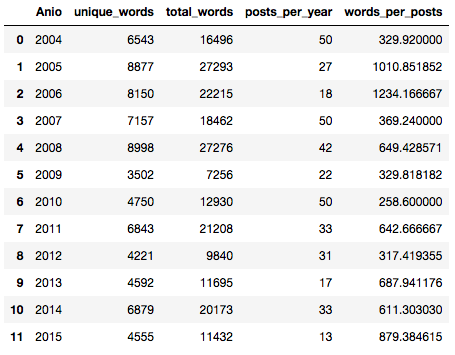
Ahora sacaremos algunas estadísticas de palabras únicas por año (el tamaño del vocabulario empleado) y el promedio de palabras por artículo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# Find the number of unique words per Year # Identify the non-zero items in the document-term matrix, meaning that the word occurs at least once unique_list = [] for anio in data.columns: uniques = data[anio].nonzero()[0].size unique_list.append(uniques) # Create a new dataframe that contains this unique word count data_words = pd.DataFrame(list(zip(anios, unique_list)), columns=['Anio', 'unique_words']) #data_unique_sort = data_words.sort_values(by='unique_words') data_unique_sort = data_words # sin ordenar data_unique_sort # ejecuta este si hicimos el webscrapping, o no tenemos los valores en la variable posts_per_year=[] try: enlaces except NameError: # Si no hice, los tengo hardcodeados: posts_per_year = [50, 27, 18, 50, 42, 22, 50, 33, 31, 17, 33, 13] else: for i in range(len(anios)): arts = enlaces[i] #arts = arts[0:10] #limito a maximo 10 por año print(anios[i],len(arts)) posts_per_year.append(min(len(arts),MAX_POR_ANIO)) # Find the total number of words per Year total_list = [] for anio in data.columns: totals = sum(data[anio]) total_list.append(totals) # Let's add some columns to our dataframe data_words['total_words'] = total_list data_words['posts_per_year'] = posts_per_year data_words['words_per_posts'] = data_words['total_words'] / data_words['posts_per_year'] # Sort the dataframe by words per minute to see who talks the slowest and fastest #data_wpm_sort = data_words.sort_values(by='words_per_posts') data_wpm_sort = data_words #sin ordenar data_wpm_sort |
4.5.1 Visualización de la tabla
Veamos los datos en gráfico de barras horizontales:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import numpy as np plt.rcParams['figure.figsize'] = [16, 6] y_pos = np.arange(len(data_words)) plt.subplot(1, 3, 1) plt.barh(y_pos,posts_per_year, align='center') plt.yticks(y_pos, anios) plt.title('Number of Posts', fontsize=20) plt.subplot(1, 3, 2) plt.barh(y_pos, data_unique_sort.unique_words, align='center') plt.yticks(y_pos, data_unique_sort.Anio) plt.title('Number of Unique Words', fontsize=20) plt.subplot(1, 3, 3) plt.barh(y_pos, data_wpm_sort.words_per_posts, align='center') plt.yticks(y_pos, data_wpm_sort.Anio) plt.title('Number of Words Per Posts', fontsize=20) plt.tight_layout() plt.show() |
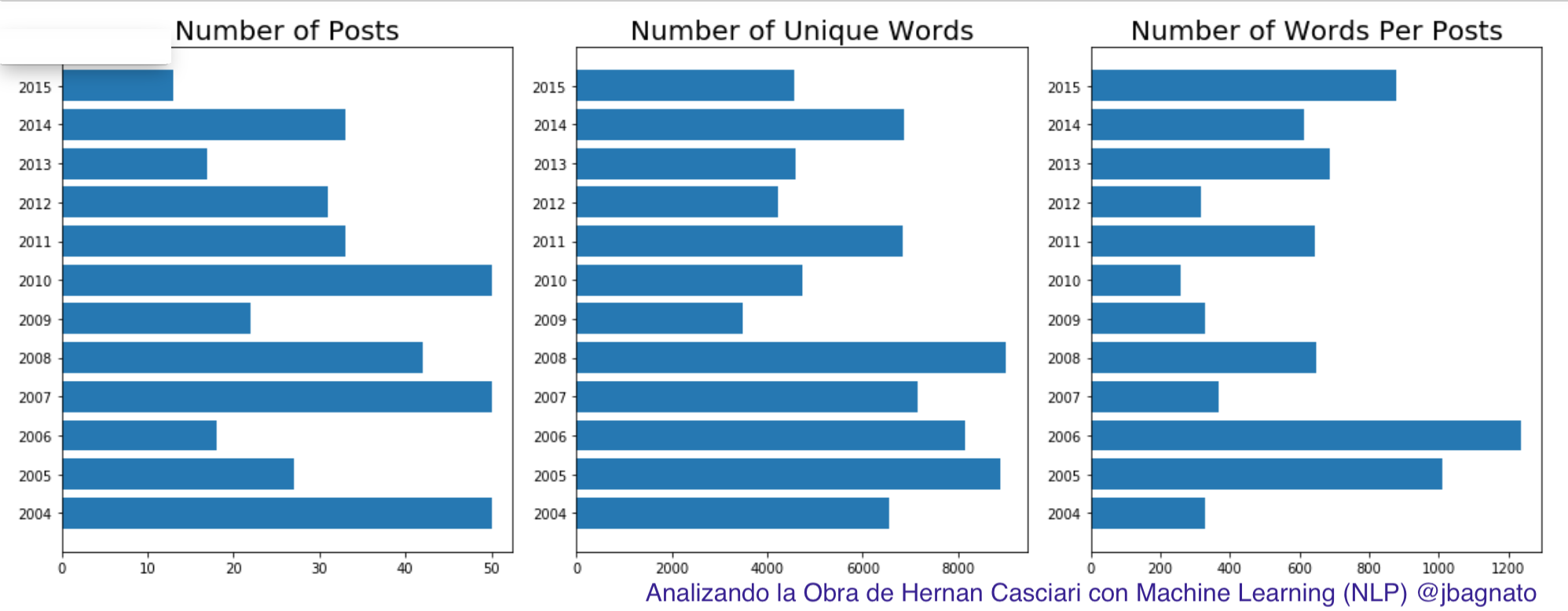
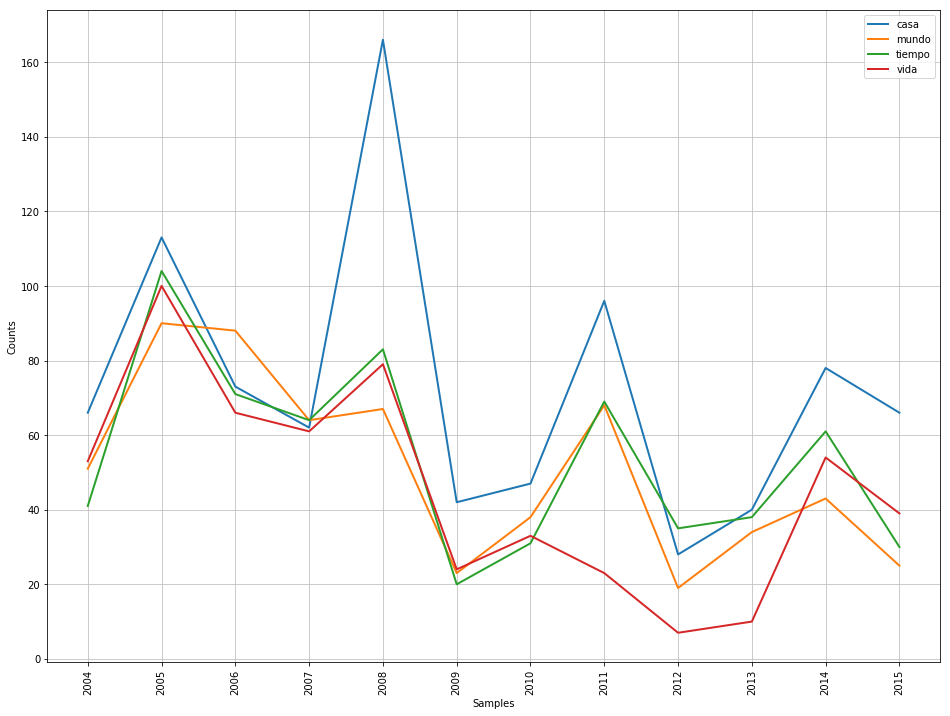
Y hagamos una comparativa de frecuencia de uso de algunas palabras (aquí tu podrías escoger otras) En mi caso seleccioné casa, mundo,tiempo y vida
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import nltk from nltk.corpus import PlaintextCorpusReader corpus_root = './python_projects/blog' wordlists = PlaintextCorpusReader(corpus_root, '.*', encoding='latin-1') #wordlists.fileids() # con esto listamos los archivos del directorio cfd = nltk.ConditionalFreqDist( (word,genre) for genre in anios for w in wordlists.words(genre + '.txt') for word in ['casa','mundo','tiempo','vida'] if w.lower().startswith(word) ) cfd.plot() |
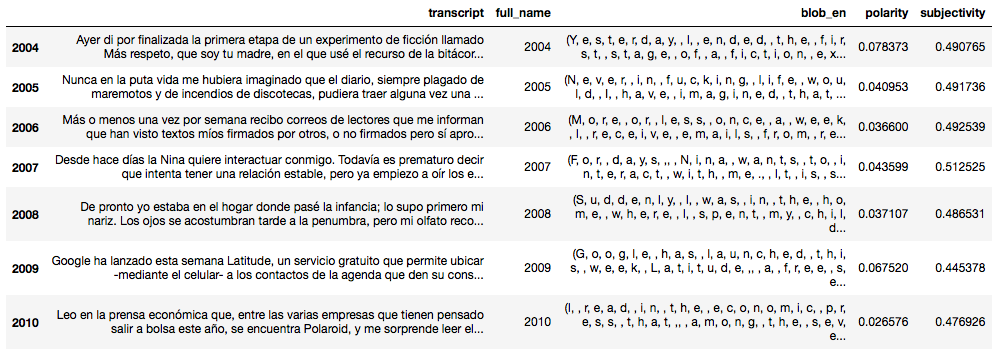
5 – Análisis de Sentimiento
Ahora probaremos analizando los sentimientos en cuanto a “positivos y negativos” encontrados en el texto y sus cambios de polaridad. Para simplificar usaremos una librería llamada TextBlob que ya tiene esta funcionalidad hecha, aunque NO LO recomiendo para uso en producción. Por desgracia sólo funciona con textos en inglés, por lo que además nos obliga a traducir el texto con lo que eso conlleva… Pero para fines educativos -cómo los de este blog- es un buen ejemplo para ver el análisis de sentimiento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
data = pd.read_pickle('corpus.pkl') from textblob import TextBlob pol = lambda x: TextBlob(x).sentiment.polarity pol2 = lambda x: x.sentiment.polarity sub = lambda x: TextBlob(x).sentiment.subjectivity sub2 = lambda x: x.sentiment.subjectivity traducir = lambda x: TextBlob(x).translate(to="en") data['blob_en'] = data['transcript'].apply(traducir) data['polarity'] = data['blob_en'].apply(pol2) data['subjectivity'] = data['blob_en'].apply(sub2) data |
5.1 Visualización global
Veamos globalmente tomando en cuenta la polaridad y la subjetividad detectadas por la librería:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
plt.rcParams['figure.figsize'] = [10, 8] for index, anio in enumerate(data.index): x = data.polarity.loc[anio] y = data.subjectivity.loc[anio] plt.scatter(x, y, color='blue') plt.text(x+.001, y+.001, data['full_name'][index], fontsize=10) plt.xlim(-0.051, 0.152) plt.title('Sentiment Analysis', fontsize=20) plt.xlabel('<-- Negative -------- Positive -->', fontsize=15) plt.ylabel('<-- Facts -------- Opinions -->', fontsize=15) plt.show() |

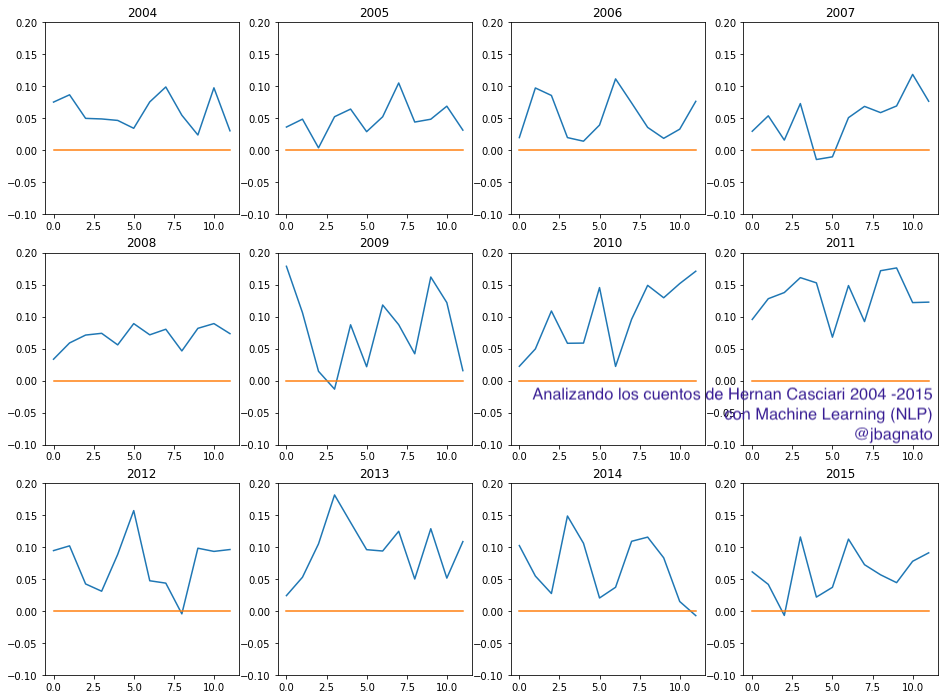
5.2 Sentimiento año por año
Ahora intentaremos analizar el comportamiento del sentimiento a medida que el autor escribía cuentos a lo largo de los años. Para ello, tomaremos de a 12 “trozos” de texto de cada año y los analizaremos. (NOTA: Esto no es preciso realmente, pues no coincide temporalmente con 12 meses, es para dar una idea al lector de las diversas técnicas que podemos aplicar).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import math def split_text(text, n=12): '''Takes in a string of text and splits into n equal parts, with a default of 12 equal parts.''' # Calculate length of text, the size of each chunk of text and the starting points of each chunk of text length = len(text) size = math.floor(length / n) start = np.arange(0, length, size) # Pull out equally sized pieces of text and put it into a list split_list = [] for piece in range(n): split_list.append(text[start[piece]:start[piece]+size]) return split_list list_pieces = [] for t in data.blob_en:#transcript: split = split_text(t,12) list_pieces.append(split) polarity_transcript = [] for lp in list_pieces: polarity_piece = [] for p in lp: #polarity_piece.append(TextBlob(p).translate(to="en").sentiment.polarity) polarity_piece.append(p.sentiment.polarity) polarity_transcript.append(polarity_piece) plt.rcParams['figure.figsize'] = [16, 12] for index, anio in enumerate(data.index): plt.subplot(3, 4, index+1) plt.plot(polarity_transcript[index]) plt.plot(np.arange(0,12), np.zeros(12)) plt.title(data['full_name'][index]) plt.ylim(ymin=-.1, ymax=.2) plt.show() |
6. Modelado de Tópicos (ó temas)
Ahora intentaremos obtener “automáticamente” algunos de los temas sobre los que escribe el autor. A decir verdad para que funcione deberíamos aplicar Lemmatization y limpiar mejor nuestro dataset. Para poder mostrar esta técnica nos vale, aunque no obtendremos resultados realmente buenos.
Utilizaremos la conocida librería Gensim y utilizaremos el algoritmo Latent Dirichlet Allocation (LDA)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
data = pd.read_pickle('dtm_stop.pkl') tdm = data.transpose() sparse_counts = scipy.sparse.csr_matrix(tdm) corpus = matutils.Sparse2Corpus(sparse_counts) cv = pickle.load(open("cv_stop.pkl", "rb")) id2word = dict((v, k) for k, v in cv.vocabulary_.items()) from nltk import word_tokenize, pos_tag def nouns_adj(text): '''Given a string of text, tokenize the text and pull out only the nouns and adjectives.''' is_noun_adj = lambda pos: pos[:2] == 'NN' or pos[:2] == 'JJ' tokenized = word_tokenize(text,language='spanish') nouns_adj = [word for (word, pos) in pos_tag(tokenized) if is_noun_adj(pos)] return ' '.join(nouns_adj) data_clean = pd.read_pickle('data_clean.pkl') data_clean from sklearn.feature_extraction import text from sklearn.feature_extraction.text import CountVectorizer # Re-add the additional stop words since we are recreating the document-term matrix #add_stop_words = ['di', 'la', 'know', 'just', 'dont', 'thats', 'right', 'people', # 'youre', 'got', 'gonna', 'time', 'think', 'yeah', 'said'] #stop_words = text.ENGLISH_STOP_WORDS.union(add_stop_words) # Add new stop words #stop_words = text.ENGLISH_STOP_WORDS.union(add_stop_words) with open('spanish.txt') as f: stop_words = f.read().splitlines()# for pal in add_stop_words: stop_words.append(pal) for pal in more_stop_words: stop_words.append(pal) # Create a new document-term matrix using only nouns and adjectives, also remove common words with max_df cvna = CountVectorizer(stop_words=stop_words, max_df=.8) data_cvna = cvna.fit_transform(data_nouns_adj.transcript) data_dtmna = pd.DataFrame(data_cvna.toarray(), columns=cvna.get_feature_names()) data_dtmna.index = data_nouns_adj.index data_dtmna data_nouns_adj = pd.DataFrame(data_clean.transcript.apply(nouns_adj)) data_nouns_adj # Create the gensim corpus corpusna = matutils.Sparse2Corpus(scipy.sparse.csr_matrix(data_dtmna.transpose())) # Create the vocabulary dictionary id2wordna = dict((v, k) for k, v in cvna.vocabulary_.items()) # Probamos a modelar con 3 tópicos ldana = models.LdaModel(corpus=corpusna, num_topics=3, id2word=id2wordna, passes=10) ldana.print_topics() |
6.1 Identificar los temas
Ahora haremos una “pasada” más profunda para ver si obtenemos 3 temáticas diferenciadas:
|
1 2 3 |
QTY_TOPICS=3 ldana = models.LdaModel(corpus=corpusna, num_topics=QTY_TOPICS, id2word=id2wordna, passes=80) ldana.print_topics() |
|
1 |
[(0,<br> '0.001<em>"jugador" + 0.001</em>"papelitos" + 0.001<em>"niño" + 0.001</em>"casciari" + 0.001<em>"luis" + 0.001</em>"charla" + 0.001<em>"luna" + 0.001</em>"monedas" + 0.001<em>"quizás" + 0.001</em>"blogs"'),<br> (1,<br> '0.002<em>"casciari" + 0.001</em>"cuaderno" + 0.001<em>"jorge" + 0.001</em>"colo" + 0.001<em>"cuadernos" + 0.001</em>"waiser" + 0.001<em>"coche" + 0.001</em>"mundiales" + 0.001<em>"goles" + 0.001</em>"messi"'),<br> (2,<br> '0.002<em>"comequechu" + 0.002</em>"proyecto" + 0.001<em>"textos" + 0.001</em>"próximo" + 0.001<em>"páginas" + 0.001</em>"corbata" + 0.001<em>"librero" + 0.001</em>"libreros" + 0.001<em>"sant" + 0.001</em>"celoni"')] |
|
1 2 |
corpus_transformed = ldana[corpusna] list(zip([a for [(a,b)] in corpus_transformed], data_dtmna.index)) |
|
1 |
[(1, '2004'),<br> (1, '2005'),<br> (2, '2006'),<br> (3, '2007'),<br> (2, '2008'),<br> (1, '2009'),<br> (3, '2010'),<br> (2, '2011'),<br> (1, '2012'),<br> (1, '2013'),<br> (1, '2014'),<br> (3, '2015')]<br> |
podemos intuir (¿forzosamente?) que lo que detectó el algoritmo se refiere a estos 3 temas:
- Jugar / Niñez
- Fútbol
- Futuro
Conclusiones finales
Repasemos lo que hicimos y que resultados sacamos:
- Extracción de 386 textos -> conseguimos los cuentos de 2004 al 2015
- Limpiamos los textos, quitamos caracteres que no utilizamos y creamos un listado de stop_words (palabras para omitir)
- Exploración de datos:
- Realizamos estadísticas básicas, como el vocabulario usado, cantidad de palabras por año y promedio por posts.
- Creamos Nubes de Palabras por año ya que es una manera de visualizar textos
- Análisis de Sentimiento: visualizamos las variaciones en los textos a lo largo del tiempo y vimos leves sobresaltos, pero por lo general, una tendencia neutral.
- Modelado de temáticas: en este punto no creo que hayamos conseguido unas categorías muy definidas. Parte del problema es que no pudimos hacer Lemmatization pues no conseguí herramientas Python en Español. Otra opción es que no hay temáticas claras.
ATENCIóN: este artículo es algo “estándar”, como para comenzar a entender el NLP aplicado y cómo -con diversas técnicas- comprender el lenguaje humano. Realmente hay muchas más aplicaciones y tareas que se pueden hacer. Debo decir que casi todo “en el mercado” está hecho para analizar textos en inglés y parte de la dificultad para desarrollar el ejercicio consistió en llevarlo al castellano. Si conoces otras buenas herramientas en español, escríbeme!
ATENCIóN (2): Podrás encontrar diferencias entre las visualizaciones en este artículo y el último Jupyter Notebook colgado en Github, esto se debe a que hubo actualizaciones en el código que no están reflejados en el artículo.
Espero en el futuro poder mostrar más utilidades del NLP y también llegar a usar NLP con algoritmos de Deep Learning (por ejemplo con redes neuronales convolucionales).
Suscripción al Blog
Recibe los nuevos artículos sobre Machine Learning, redes neuronales, NLP y código Python cada 3 semanas aprox.
Recursos – Descarga el código
- Ver código completo Python y archivos en Github
- Ver/Descarga el Jupyter Notebook completo aqui
- y no olvides de las stop words: spanish.txt (esto es si no lo tienes descargado por NLTK)
- Si no haces el web scrapping, puedes descargar un zip con los textos del blog de casciari en txt
- Recuerda que para el ejercicio deberás instalar las librerías Python adicionales:
- WordCloud
- Gensim
- TextBlob
- Si te salteaste la teoría te recomiendo que leas mi artículo anterior, Introducción al Procesamiento del Lenguaje Natural (sólo teoría) NLP
- Puedes leer mi artículo sobre cómo hacer WebScraping de cualquier página web
Enlaces para seguir con NLP!
- Descube qué son los Transformers y por qué son la revolución en NLP y en todo el Machine Learning!
- Ejercicio práctico en Python: Tu propio generador de textos en Español con GPT-2
Hola, como podría trabajar Lemmatization para textos en castellano?
Muchas gracias por compartir tan magnífico trabajo.
Hola Emilio, gracias por escribir! Saludos
sos un genio!! grandisimo aporte… Tengo un caso concreto que estoy interesado en desarrollar con mi equipo. Esta relacionado con interpretacion de emails para poder automatizar las respuestas ( utilizando tecnologia de automatizacion de procesos (RPA) ) si te interesa colaborar, serias mas que bienvenido 😀
Hola! El formato dle blog de Casciari cambio un poco
Deberias cambiar la funcion url_get_text() a:
def url_get_text(url):
”’Obtener los textos de los cuentos de Hernan Casciari.”’
print(‘URL’,url)
text=””
try:
page = requests.get(url).text
soup = BeautifulSoup(page, “lxml”)
text = [p.text for p in soup.find(class_=”section-single-content”).find_all(‘p’)]
except Exception:
print(‘ERROR, puede que un firewall nos bloquea.’)
return ”
sleep(0.75) #damos tiempo para que no nos penalice un firewall
return text
Gracias hombre, muy buen dato!
Excelente ejemplo, muchas gracias!!
Muchas gracias por esta información, estoy iniciando en el uso de Python y en el tema de la NLP. Te comento que he seguido paso a paso el ejercicio; sin embargo, se me presentó un problema cuando quiero acceder al sitio web y es que no puedo establecer una conexión con la dirección URL que se indica en el código.
Podrías indicarme en donde puede estar mi error.
El mensaje que me muestra es el siguiente:
ConnectionError: HTTPSConnectionPool(host=’editorialorsai.com’, port=443): Max retries exceeded with url: /category/epocas/2004/ (Caused by NewConnectionError(‘: Failed to establish a new connection: [WinError 10061] No se puede establecer una conexión ya que el equipo de destino denegó expresamente dicha conexión’))
Hola Maria, gracias por comentar. El error informa que la web desde donde intentas extraer la información (de los cuentos de Casciari) ha denegado tu request. Esto puede ser porque hayas hecho demasiadas peticiones en poco tiempo y te hayan confundido con un ataque DDos ú otro agente malicioso.
Deberás esperar y tratar bien al servidor 🙂
saludos,
El sitio parece haber sido sustituido por otro que no contiene cuentos. Es una empresa llamada «Orsai Audiovisuales».
Hola! Yo tmb econtré ese problema, pero ya pude hallar el blog del escritor. Sin embargo, ahora el sitio base es https://hernancasciari.com/blog/‘, pero el código lanza un error FileNotFoundError: [Errno 2] No such file or directory: ‘blog/2003.txt’ creo que esto es por que el sitio web ya no tiene las mismas URL´s, pero no he sabido como adaptarlo. Agradecería mucho un update de esto! muchas gracias es un ejercicio muy bueno