Crea imágenes increíbles con Inteligencia Artificial en tu ordenador
El modelo de Machine Learning llamado Stable Diffusion es Open Source y permite generar cualquier imagen a partir de un texto, por más loca que sea, desde el sofá de tu casa!

Estamos viviendo unos días realmente emocionantes en el campo de la inteligencia artificial, en apenas meses, hemos pasado de tener modelos enormes y de pago en manos de unas pocas corporaciones a poder desplegar un modelo en tu propio ordenador y lograr los mismos -increíbles- resultados de manera gratuita. Es decir, ahora mismo, está al alcance de prácticamente cualquier persona la capacidad de utilizar esta potentísima herramienta y crear imágenes en segundos (ó minutos) y a coste cero.
En este artículo les comentaré qué es Stable Diffusion y por qué es un hito en la historia de la Inteligencia Artificial, veremos cómo funciona y tienes la oportunidad de probarlo en la nube o de instalarlo en tu propio ordenador sea Windows, Linux ó Mac, con o sin placa GPU.
Reseña de los acontecimientos
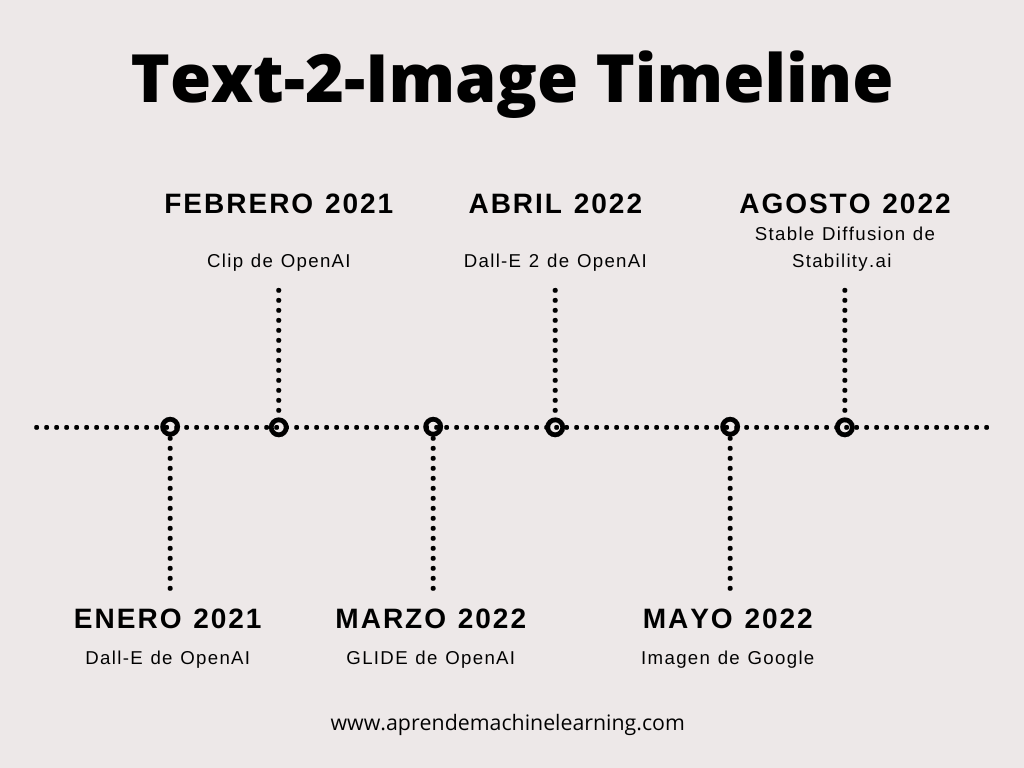
- 2015: Paper que propone los Diffusion Models.
- 2018 -2019 Text to Image Synthesis – usando GANS se generan imágenes de 64×64 pixels, utiliza muchos recursos y baja calidad de resultados.
- Enero 2021: Open AI anuncia Dall-E, genera imágenes interesantes, pequeñas, baja resolución, lentas.
- Febrero 2021: CLIP de Open AI (Contrastive Language-Image Pretraining), un codificador dual de lenguaje-imagen muy potente.
- Julio 2021: Image Text Contrastive Learning Mejora sobre las Gans “image-text-label” space.
- Marzo 2022: GLIDE: esta red es una mejora sobre Dall-E, tambien de openAI pero usando DIFFUSION model.
- Abril 2022: Dall-E 2 de Open AI, un modelo muy bueno de generación de imágenes. Código cerrado, acceso por pedido y de pago.
- Mayo 2022: Imagen de Google.
- Agosto de 2022: Lanzamiento de Stable Diffusion 1.4 de Stability AI al público. Open Source, de bajos recursos, para poder ejecutar en cualquier ordenador.
¿Qué es Stable Diffusion?

Stable Diffusion es el nombre de un nuevo modelo de Machine Learning de Texto-a-Imagen creado por Stability Ai, Comp Vis y LAION. Entrenado con +5 mil millones de imágenes del dataset Laion-5B en tamaño 512 por 512 pixeles. Su código fue liberado al público el 22 de Agosto de 2022 y en un archivo de 4GB con los pesos entrenados de una red neuronal que podemos descargar desde HuggingFace, tienes el poder de crear imágenes muy diversas a partir de una entrada de texto.
Stable Diffusion es también una gran revolución en nuestra sociedad porque trae consigo diversas polémicas; al ofrecer esta herramienta a un amplio público, permite generar imágenes de fantasía de paisajes, personas, productos… ¿cómo afecta esto a los derechos de autor? Qué pasa con las imágenes inadecuadas u ofensivas? Qué pasa con el sesgo de género? Puede suplantar a un diseñador gráfico? Hay un abanico enorme de incógnitas sobre cómo será utilizada esta herramienta y la disrupción que supone. A mí personalmente me impresiona por el progreso tecnológico, por lo potente que es, los magnificos resultados que puede alcanzar y todo lo positivo que puede acarrear.
¿Por qué tanto revuelo? ¿Es como una gran Base de datos de imágenes? – ¡No!
Es cierto que fue entrenada con más de 5 mil millones de imágenes. Entonces podemos pensar: “Si el modelo vio 100.000 imágenes de caballos, aprenderá a dibujar caballos. Si vio 100.000 imágenes de la luna, sabrá pintar la luna. Y si aprendió de miles de imágenes de astronautas, sabrá pintar astronautas“. Pero si le pedimos que pinte “un astronauta a caballo en la luna” ¿qué pasa? La respuesta es que el modelo que jamás había visto una imagen así, es capaz de generar cientos de variantes de imágenes que cumplen con lo solicitado… esto ya empieza a ser increíble. Podemos pensar: “Bueno, estará haciendo un collage, usando un caballo que ya vio, un astronauta (que ya vió) y la luna y hacer una composición“. Y no; no es eso lo que hace, ahí se vuelve interesante: el modelo de ML parte de un “lienzo en blanco” (en realidad es una imagen llena de ruido) y a partir de ellos empieza a generar la imagen, iterando y refinando su objetivo, pero trabajando a nivel de pixel (por lo cual no está haciendo copy-paste). Si creyéramos que es una gran base de datos, les aseguro que no caben las 5.500.000.000 de imágenes en 4 Gygabytes -que son los pesos del modelo de la red- pues estaría almacenando cada imagen (de 512x512px) en menos de 1 Byte, algo imposible.
¿Cómo funciona Stable Diffusion?
Veamos cómo funciona Stable Diffusion!
Seguir Leyendo