Crea en Python un motor de recomendación con Collaborative Filtering
Una de las herramientas más conocidas y utilizadas que aportó el Machine Learning fueron los sistemas de Recomendación. Son tan efectivas que estamos invadidos todos los días por recomendaciones, sugerencias y “productos relacionados” aconsejados por distintas apps y webs.
Sin dudas, los casos más conocidos de uso de esta tecnología son Netflix acertando en recomendar series y películas, Spotify sugiriendo canciones y artistas ó Amazon ofreciendo productos de venta cruzada <<sospechosamente>> muy tentadores para cada usuario.
Pero también Google nos sugiere búsquedas relacionadas, Android aplicaciones en su tienda y Facebook amistades. O las típicas “lecturas relacionadas” en los blogs y periódicos.
Todo E-Comerce que se precie de serlo debe utilizar esta herramienta y si no lo hace… estará perdiendo una ventaja competitiva para potenciar sus ventas.
Si vas por el buen camino hacia el aprendizaje del Machine Learning, la inteligencia artificial y la ciencia de datos, seguramente te hayas topado con trabas y obstáculos frecuentes. En este artículo repasaremos 12 útiles consejos para tener en cuenta a la hora de trabajar con los modelos del Aprendizaje Automático. Estos postulados surgen del paper “A Few Useful Things to Know about Machine Learning“ escrito en 2012 por Pedro Domingos.
Con el objetivo de ilustrar mejor estos consejos, nos centraremos en la aplicación del Machine Learning de Clasificar, pero esto podría servir para otros usos.
Los 3 componentes del Aprendizaje Automático
Supongamos que tienes un problema al que crees que puedes aplicar ML. ¿Qué modelo usar? Deberá ser una combinación de estos 3 componentes: Representación, evaluación y optimización.
Representación: Un clasificador deberá poder ser representado en un lenguaje formal que entienda el ordenador. Deberemos elegir entre los diversos algoritmos que sirven para resolver el problema. A este conjunto de “clasificadores aptos” se les llamará “espacio de hipótesis del aprendiz”. Ej: SVM, Regresión Logística, K-nearest neighbor, árboles de decisión, Redes Neuronales, etc.
Evaluación: Se necesitará una función de evaluación para distinguir entre un buen clasificador ó uno malo. También es llamada función objetivo ó scoring function. Ejemplos son accuracy, likelihood, information gain, etc.
Optimización: necesitamos un método de búsqueda entre los clasificadores para mejorar el resultado de la Evaluación. Su elección será clave. EJ: Descenso por gradiente, mínimos cuadrados, etc.
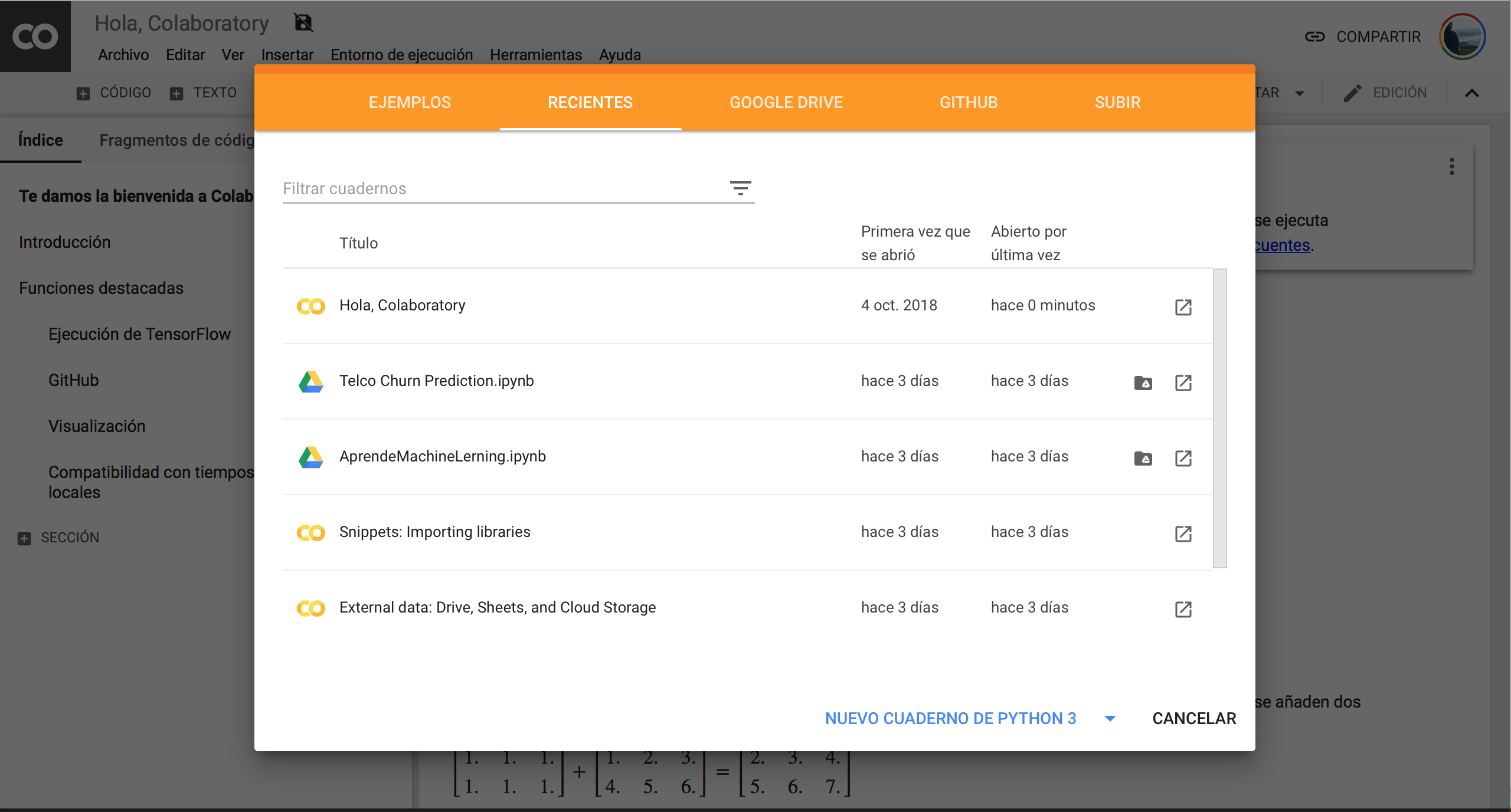
Por increíble que parezca, ahora mismo tenemos disponible una cuenta gratuita para programar nuestros modelos de Machine Learning en la nube, con Python, Jupyter Notebooks de manera remota y hasta con GPU para poder aumentar nuestro poder de procesamiento…. gratis! sí sí… esto no es un “cuento del tío” ni tiene ninguna trampa!… Descubre cómo aprovecharlo en este artículo!
Machine Learning desde el Navegador
Primero lo primero. ¿Porqué voy a querer tener mi código en la nube? Pues bien, lo normal (¿ideal?) es que tengamos un entorno de desarrollo local en nuestro propio ordenador, un entorno de pruebas en algún servidor, staging y producción. Pero… ¿qué pasa si aún no tenemos instalado el ambiente?, o tenemos conflictos con algún archivo/librería, versión de Python… ó por lo que sea no tenemos espacio en disco… ó hasta si nos va muy lento y no disponemos en -el corto plazo- de mayor procesador/ram? O hasta por simple comodidad, está siempre bien tener a mano una web online, “siempre lista” en donde ya esté prácticamente todo el software que necesitamos instalado. Y ese servicio lo da Google, entre otras opciones. Lo interesante es que Google Colab ofrece varias ventajas frente a sus competidores.
interesante es que Google Colab ofrece varias ventajas frente a sus competidores.
La GPU…. ¿en casa o en la nube?
¿Una GPU? ¿para que quiero eso si ya tengo como 8 núcleos? La realidad es que para el procesamiento de algoritmos de Aprendizaje Automático (y para videojuegos, ejem!) la GPU resulta mucho más potente en realizar cálculos (también en paralelo) por ejemplo las multiplicaciones matriciales… esas que HACEMOS TOooooDO el tiempo al ENTRENAR nuestros modelos!!! para hacer el descenso por gradiente ó Toooodo el rato con el Backpropagation de nuestras redes neuronales… Esto supone una mejora de hasta 10x en velocidad de procesado… Algoritmos que antes tomaban días y ahora se resuelven en horas. Un avance enorme.
Si tienes una tarjeta Nvidia con GPU ya instalada, felicidades ya tienes el poder! Si no la tienes y no vas a invertir unos cuántos dólares en comprarla, puedes tener toda(*) su potencia desde la nube!
(*)NOTA: Google se reserva el poder limitar el uso de GPU si considera que estás abusando ó utilizando en demasía ese recurso ó para fines indebidos (por ej. minería de bitcoins)
El Procesamiento del Lenguaje Natural (NLP por sus siglas en inglés) es el campo de estudio que se enfoca en la comprensión mediante ordenador del lenguaje humano. Abarca parte de la Ciencia de Datos, Inteligencia Artificial (Aprendizaje Automático) y la lingüística.
En NLP las computadoras analizan el leguaje humano, lo interpretan y dan significado para que pueda ser utilizado de manera práctica. Usando NLP podemos hacer tareas como resumen automático de textos, traducción de idiomas, extracción de relaciones, Análisis de sentimiento, reconocimiento del habla y clasificación de artículos por temáticas.
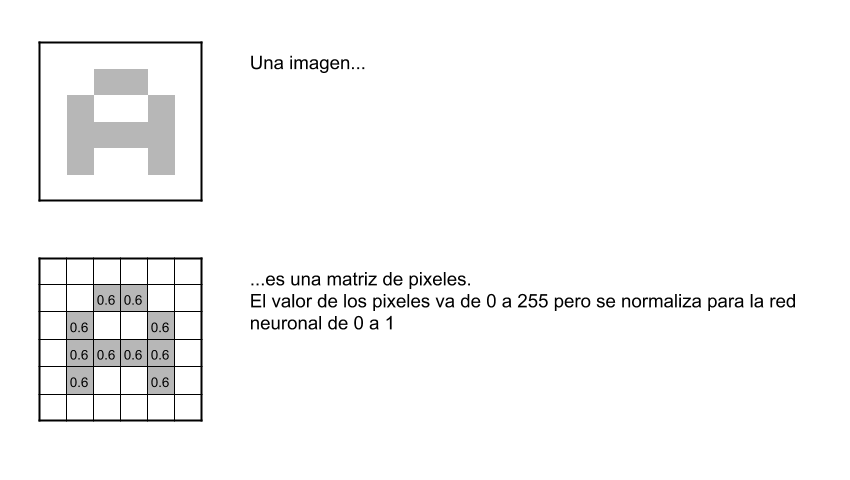
En este artículo intentaré explicar la teoría relativa a las Redes Neuronales Convolucionales (en inglés CNN) que son el algoritmo utilizado en Aprendizaje Automático para dar la capacidad de “ver” al ordenador. Gracias a esto, desde apenas 1998, podemos clasificar imágenes, detectar diversos tipos de tumores automáticamente, enseñar a conducir a los coches autónomos y un sinfín de otras aplicaciones.
El tema es bastante complejo/complicado e intentaré explicarlo lo más claro posible. En este artículo doy por sentado que tienes conocimientos básicos de cómo funciona una red neuronal artificial multicapa feedforward (fully connected). Si no es así te recomiendo que antes leas sobre ello:
¿Qúe es una CNN? ¿Cómo puede ver una red neuronal? ¿Cómo clasifica imagenes y distingue un perro de un gato?
La CNN es un tipo de Red Neuronal Artificial con aprendizaje supervisado que procesa sus capas imitando al cortex visual del ojo humano para identificar distintas características en las entradas que en definitiva hacen que pueda identificar objetos y “ver”. Para ello, la CNN contiene varias capas ocultas especializadas y con una jerarquía: esto quiere decir que las primeras capas pueden detectar lineas, curvas y se van especializando hasta llegar a capas más profundas que reconocen formas complejas como un rostro o la silueta de un animal.
Necesitaremos…
Recodemos que la red neuronal deberá aprender por sí sola a reconocer una diversidad de objetos dentro de imágenes y para ello necesitaremos una gran cantidad de imágenes -lease más de 10.000 imágenes de gatos, otras 10.000 de perros,…- para que la red pueda captar sus características únicas -de cada objeto- y a su vez, poder generalizarlo -esto es que pueda reconocer como gato tanto a un felino negro, uno blanco, un gato de frente, un gato de perfil, gato saltando, etc.-
Ejercicio Propuesto: Clasificar imágenes de deportes
Para el ejercicio se me ocurrió crear “mi propio set MNIST” con imágenes de deportes. Para ello, seleccioné los 10 deportes más populares del mundo -según la sabiduría de internet- : Fútbol, Basket, Golf, Futbol Americano, Tenis, Fórmula 1, Ciclismo, Boxeo, Beisball y Natación (enumerados sin orden particular entre ellos).
Obtuve entre 5000 y 9000 imágenes de cada deporte, a partir de videos de Youtube (usando a FFMpeg!). Las imágenes están en tamaño <<diminuto>> de 21×28 pixeles en color y son un total de 77.000. Si bien el tamaño en pixeles puede parecer pequeño ES SUFICIENTE para que nuestra red neuronal pueda distinguirlas!!! (¿increíble, no?).
Entonces el objetivo es que nuestra máquina: “red neuronal convolucional” aprenda a clasificar -por sí sóla-, dada una nueva imagen, de qué deporte se trata.
Ejemplo de imágenes de los deportes más populares del mundo
Dividiremos el set de datos en 80-20 para entrenamiento y para test. A su vez, el conjunto de entrenamiento también lo subdividiremos en otro 80-20 para Entrenamiento y Validación en cada iteración (EPOCH) de aprendizaje.
Una muestra de las imágenes del Dataset que he titulado sportsMNIST. Contiene más de 70.000 imágenes de los 10 deportes más populares del mundo.