
En el artículo de hoy veremos qué son las series temporales y cómo predecir su comportamiento utilizando redes neuronales con Keras y Tensorflow. Repasaremos el código completo en Python y la descarga del archivo csv del ejercicio propuesto con los datos de entrada.

¿Qué es una serie temporal y qué tiene de especial?
Una serie temporal es un conjunto de muestras tomadas a intervalos de tiempo regulares. Es interesante analizar su comportamiento al mediano y largo plazo, intentando detectar patrones y poder hacer pronósticos de cómo será su comportamiento futuro. Lo que hace <<especial>> a una Time Series a diferencia de un “problema” de Regresión son dos cosas:
- Es dependiente del Tiempo. Esto rompe con el requerimiento que tiene la regresión lineal de que sus observaciones sean independientes.
- Suelen tener algún tipo de estacionalidad, ó de tendencias a crecer ó decrecer. Pensemos en cuánto más producto vende una heladería en sólo 4 meses al año que en el resto de estaciones.
Ejemplo de series temporales son:
- Capturar la temperatura, humedad y presión de una zona a intervalos de 15 minutos.
- Valor de las acciones de una empresa en la bolsa minuto a minuto.
- Ventas diarias (ó mensuales) de una empresa.
- Producción en Kg de una cosecha cada semestre.
Creo que con eso ya se dan una idea 🙂 Como también pueden entrever, las series temporales pueden ser de 1 sóla variable, ó de múltiples.
Vamos a comenzar con la práctica, cargando un dataset que contiene información de casi 2 años de ventas diarias de productos. Los campos que contiene son fecha y la cantidad de unidades vendidas.
Requerimientos para el Ejercicio
Como siempre, para poder realizar las prácticas, les recomiendo tener instalado un entorno Python 3.6 como el de Anaconda que ya nos provee las Jupyter Notebooks como se explica en este artículo. También se puede ejecutar en línea de comandos sin problemas. Este ejercicio además requiere tener instalado Keras y Tensorflow (u otro similar), como se explica en el artículo antes mencionado.
Al final del texto entontrarás enlaces al GitHub con la Notebook y el enlace de descarga del archivo csv del ejemplo.
Cargar el Ejemplo con librería Pandas
Aprovecharemos las bondades de Pandas para cargar y tratar nuestros datos. Comenzamos importando las librerías que utilizaremos y leyendo el archivo csv.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd import numpy as np import matplotlib.pylab as plt %matplotlib inline plt.rcParams['figure.figsize'] = (16, 9) plt.style.use('fast') from keras.models import Sequential from keras.layers import Dense,Activation,Flatten from sklearn.preprocessing import MinMaxScaler df = pd.read_csv('time_series.csv', parse_dates=[0], header=None,index_col=0, squeeze=True,names=['fecha','unidades']) df.head() |
fecha
2017-01-02 236
2017-01-03 237
2017-01-04 290
2017-01-05 221
2017-01-07 128
Name: unidades, dtype: int64
Notemos una cosa antes de seguir: el dataframe que cargamos con pandas tiene como Indice nuestra primera columna con las fechas. Esto es para que nos permita hacer filtrados por fecha directamente y algunas operaciones especiales.
Por ejemplo, podemos ver de qué fechas tenemos datos con:
|
1 2 |
print(df.index.min()) print(df.index.max()) |
2017-01-02 00:00:00
2018-11-30 00:00:00
Presumiblemente tenemos las ventas diarias de 2017 y de 2018 hasta el mes de noviembre. Y ahora veamos cuantas muestras tenemos de cada año:
|
1 2 |
print(len(df['2017'])) print(len(df['2018'])) |
315
289
Como este comercio cierra los domingos, vemos que de 2017 no tenemos 365 días como erróneamente podíamos presuponer. Y en 2018 nos falta el último mes… que será lo que trataremos de pronosticar.
Visualización de datos
Veamos algunas gráficas sobre los datos que tenemos. Pero antes… aprovechemos los datos estadísticos que nos brinda pandas con describe()
|
1 |
df.describe() |
count 604.000000
mean 215.935430
std 75.050304
min 51.000000
25% 171.000000
50% 214.000000
75% 261.250000
max 591.000000
Name: unidades, dtype: float64
Son un total de 604 registros, la media de venta de unidades es de 215 y un desvío de 75, es decir que por lo general estaremos entre 140 y 290 unidades.
De hecho aprovechemos el tener indice de fechas con pandas y saquemos los promedios mensuales:
|
1 2 |
meses =df.resample('M').mean() meses |
fecha
2017-01-31 203.923077
2017-02-28 184.666667
2017-03-31 182.964286
2017-04-30 198.960000
2017-05-31 201.185185
2017-06-30 209.518519
2017-07-31 278.923077
2017-08-31 316.000000
2017-09-30 222.925926
2017-10-31 207.851852
2017-11-30 185.925926
2017-12-31 213.200000
2018-01-31 201.384615
2018-02-28 190.625000
2018-03-31 174.846154
2018-04-30 186.000000
2018-05-31 190.666667
2018-06-30 196.037037
2018-07-31 289.500000
2018-08-31 309.038462
2018-09-30 230.518519
2018-10-31 209.444444
2018-11-30 184.481481
Freq: M, Name: unidades, dtype: float64
Y visualicemos esas medias mensuales:
|
1 2 |
plt.plot(meses['2017'].values) plt.plot(meses['2018'].values) |
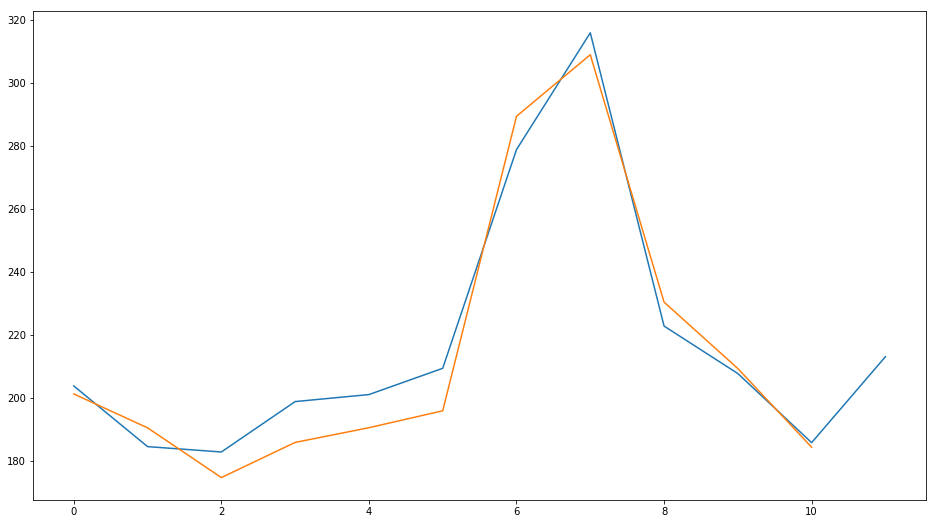
Vemos que en 2017 (en azul) tenemos un inicio de año con un descenso en la cantidad de unidades, luego comienza a subir hasta la llegada del verano europeo en donde en los meses junio y julio tenemos la mayor cantidad de ventas. Finalmente vuelve a disminuir y tiene un pequeño pico en diciembre con la Navidad.
También vemos que 2018 (naranja) se comporta prácticamente igual. Es decir que pareciera que tenemos una estacionalidad. Por ejemplo podríamos aventurarnos a pronosticar que “el verano de 2019 también tendrá un pico de ventas”.
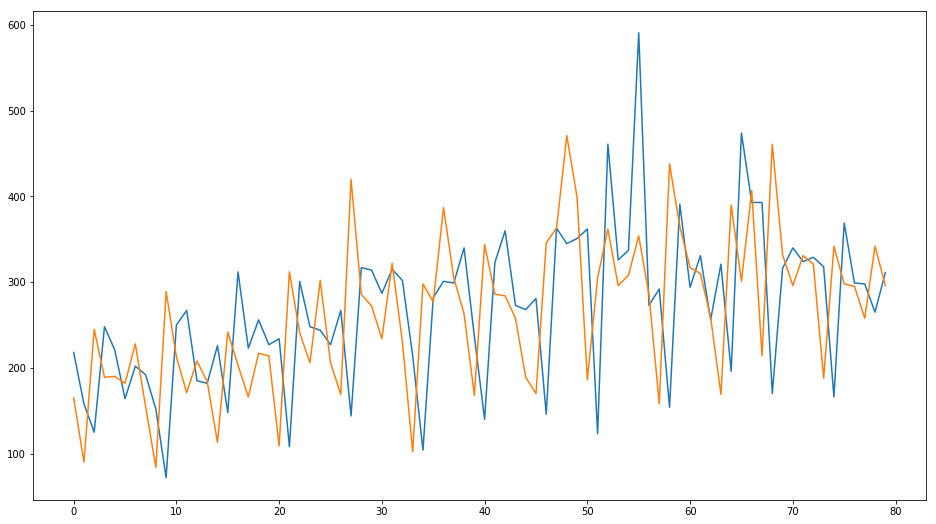
Veamos la gráfica de ventas diarias (en unidades) en junio y julio
|
1 2 3 4 |
verano2017 = df['2017-06-01':'2017-09-01'] plt.plot(verano2017.values) verano2018 = df['2018-06-01':'2018-09-01'] plt.plot(verano2018.values) |
¿Cómo hacer pronóstico de series temporales?
Una vez que tenemos confirmado que nuestra serie es estacionaria, podemos hacer pronóstico. Existen diversos métodos para hacer pronóstico. En nuestro caso, las ventas parecen comportarse bastante parecidas al año, con lo cual un método sencillo si por ejemplo quisiéramos proveer el stock que necesitaría este comercio, sería decir “Si en 2017 en diciembre vendimos promedio 213 unidades, pronostico que en diciembre será similar”. Otro método muy utilizado en estadística es el llamado ARIMA, el cual no explicaré aquí, pero les dejo un enlace por si están interesados. Aquí un gráfica que encontré en Twitter sobre la evolución del Forecasting:

Pues nosotros que somos unos alumnos tan avanzados y aplicados utilizaremos Machine Learning: una red neuronal para hacer el pronóstico. Curiosamente crear esta red es algo relativamente sencillo, y en poco tiempo estaremos usando un modelo de lo más moderno para hacer el pronóstico.
Pronóstico de Ventas Diarias con Redes Neuronal
Usaremos una arquitectura sencilla de red neuronal FeedForward (también llamada MLP por sus siglas Multi-Layered Perceptron), con pocas neuronas y como método de activación tangente hiperbólica pues entregaremos valores transformados entre -1 y 1.
Si aún no manejas del todo bien redes Neuronales, te recomiendo repasar rápidamente estos artículos y luego continuar con el ejercicio:
- Deep Learning, una guía rápida
- Crea un Red Neuronal con Keras y Tensorflow
- Crea una Red Neuronal desde cero
- Historia de las RRNN
Vamos al ejemplo!
Preparamos los datos
Este puede que sea uno de los pasos más importantes de este ejercicio.
Lo que haremos es alterar nuestro flujo de entrada del archivo csv que contiene una columna con las unidades despachadas, y lo convertiremos en varias columnas. ¿Y porqué hacer esto? En realidad lo que haremos es tomar nuestra serie temporal y la convertiremos en un “problema de tipo supervisado“ para poder alimentar nuestra red neuronal y poder entrenarla con backpropagation (“como es habitual”). Para hacerlo, debemos tener unas entradas y unas salidas para entrenar al modelo.
Lo que haremos -en este ejemplo- es tomar los 7 días previos para “obtener” el octavo. Podríamos intentar entrenar a la red con 2, ó 3 días. O también podríamos tener 1 sola salida, ó hasta “atrevernos” intentar predecir más de un “día futuro”. Eso lo dejo a ustedes cómo actividad extra. Pero entonces quedémonos con que:
- Entradas: serán “7 columnas” que representan las ventas en unidades de los 7 días anteriores.
- Salida: El valor del “8vo día”. Es decir, las ventas (en unids) de ese día.
Para hacer esta transformación usaré una función llamada series_to_supervised() creada y explicada en este blog. (La verás en el código, a continuación)
Antes de usar la función, utilizamos el MinMaxScaler para transformar el rango de nuestros valores entre -1 y 1 (pues sabemos que a nuestra red neuronal, le favorece para realizar los cálculos).
Entonces aqui vemos cómo queda nuestro set de datos de entrada.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
PASOS=7 # convert series to supervised learning def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = pd.DataFrame(data) cols, names = list(), list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)] # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j+1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)] # put it all together agg = pd.concat(cols, axis=1) agg.columns = names # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg # load dataset values = df.values # ensure all data is float values = values.astype('float32') # normalize features scaler = MinMaxScaler(feature_range=(-1, 1)) values=values.reshape(-1, 1) # esto lo hacemos porque tenemos 1 sola dimension scaled = scaler.fit_transform(values) # frame as supervised learning reframed = series_to_supervised(scaled, PASOS, 1) reframed.head() |
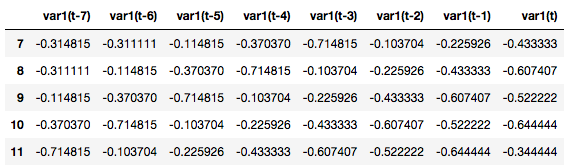
Usaremos como entradas las columnas encabezadas como var1(t-7) a (t-1) y nuestra salida (lo que sería el valor “Y” de la función) será el var1(t) -la última columna-.
¿Dudas sobre los conjuntos de Train, Test y Validación? Lee este artículo
Creamos la Red Neuronal Artificial
Antes de crear la red neuronal, subdividiremos nuestro conjunto de datos en train y en test. ATENCIÓN, algo importante de este procedimiento, a diferencia de en otros problemas en los que podemos “mezclar” los datos de entrada, es que en este caso nos importa mantener el orden en el que alimentaremos la red. Por lo tanto, haremos una subdivisión de los primeros 567 días consecutivos para entrenamiento de la red y los siguientes 30 para su validación. Esta es una proporción que elegí yo, y que me pareció conveniente, pero definitivamente, puede no ser la óptima (queda propuesto al lector, variar esta proporción por ejemplo a 80-20 y comparar resultados )
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# split into train and test sets values = reframed.values n_train_days = 315+289 - (30+PASOS) train = values[:n_train_days, :] test = values[n_train_days:, :] # split into input and outputs x_train, y_train = train[:, :-1], train[:, -1] x_val, y_val = test[:, :-1], test[:, -1] # reshape input to be 3D [samples, timesteps, features] x_train = x_train.reshape((x_train.shape[0], 1, x_train.shape[1])) x_val = x_val.reshape((x_val.shape[0], 1, x_val.shape[1])) print(x_train.shape, y_train.shape, x_val.shape, y_val.shape) |
(567, 1, 7) (567,) (30, 1, 7) (30,)
Hemos transformado la entrada en un arreglo con forma (567,1,7) esto al castellano significa algo así como “567 entradas con vectores de 1×7”.
La arquitectura de la red neuronal será:
- Entrada 7 inputs, como dijimos antes
- 1 capa oculta con 7 neuronas (este valor lo escogí yo, pero se puede variar)
- La salida será 1 sola neurona
- Como función de activación utilizamos tangente hiperbólica puesto que utilizaremos valores entre -1 y 1.
- Utilizaremos como optimizador Adam y métrica de pérdida (loss) Mean Absolute Error
- Como la predicción será un valor continuo y no discreto, para calcular el Acuracy utilizaremos Mean Squared Error y para saber si mejora con el entrenamiento se debería ir reduciendo con las EPOCHS.
|
1 2 3 4 5 6 7 8 9 |
def crear_modeloFF(): model = Sequential() model.add(Dense(PASOS, input_shape=(1,PASOS),activation='tanh')) model.add(Flatten()) model.add(Dense(1, activation='tanh')) model.compile(loss='mean_absolute_error',optimizer='Adam',metrics=["mse"]) model.summary() return model |
Entrenamiento y Resultados
Veamos cómo se comporta nuestra máquina al cabo de 40 épocas.
|
1 2 3 4 5 |
EPOCHS=40 model = crear_modeloFF() history=model.fit(x_train,y_train,epochs=EPOCHS,validation_data=(x_val,y_val),batch_size=PASOS) |
En pocos segundos vemos una reducción del valor de pérdida tanto del set de entrenamiento como del de validación.
Epoch 40/40
567/567 [==============================] – 0s 554us/step – loss: 0.1692 – mean_squared_error: 0.0551 – val_loss: 0.1383 – val_mean_squared_error: 0.03
Visualizamos al conjunto de validación (recordemos que eran 30 días)
|
1 2 3 4 5 |
results=model.predict(x_val) plt.scatter(range(len(y_val)),y_val,c='g') plt.scatter(range(len(results)),results,c='r') plt.title('validate') plt.show() |
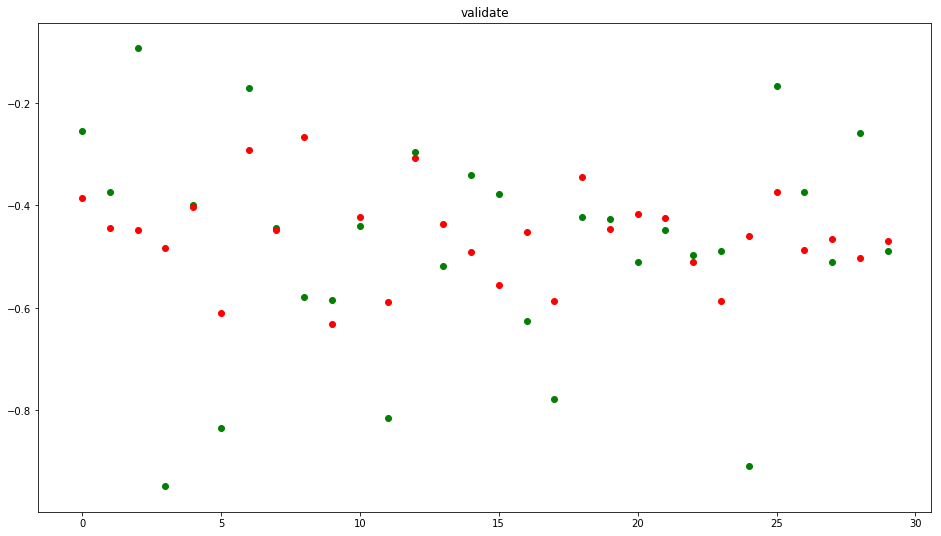
Veamos y comparemos también cómo disminuye el LOSS tanto en el conjunto de train como el de Validate, esto es bueno ya que indica que el modelo está aprendiendo. A su vez pareciera no haber overfitting, pues las curvas de train y validate son distintas.
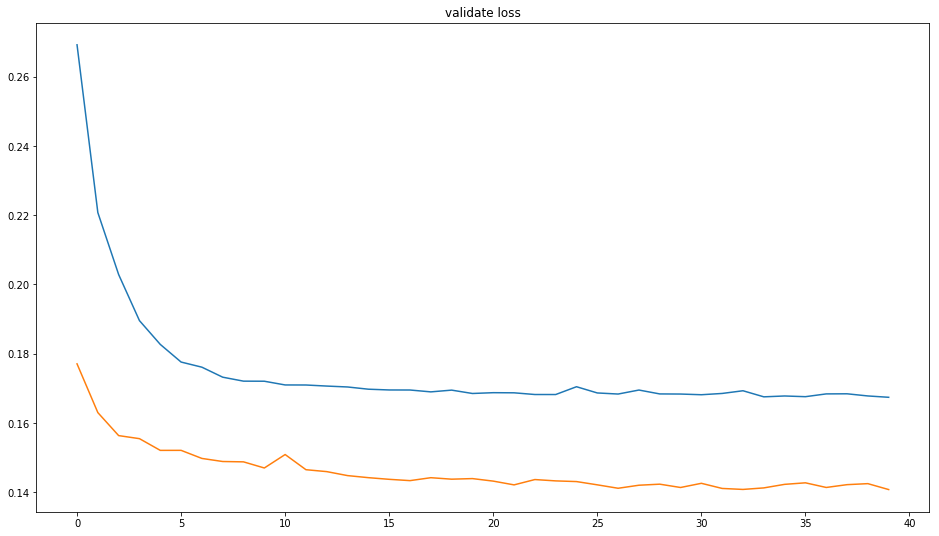
Pronóstico de ventas futuras
Ahora que tenemos nuestra red y -suponiendo que realizamos los 7 pasos del ML– la damos por buena, probaremos a realizar una nueva predicción, en este caso, usaremos los últimos días de noviembre 2018 para calcular la primer semana de diciembre. Veamos:
|
1 2 |
ultimosDias = df['2018-11-16':'2018-11-30'] ultimosDias |
fecha
2018-11-16 152
2018-11-17 111
2018-11-19 207
2018-11-20 206
2018-11-21 183
2018-11-22 200
2018-11-23 187
2018-11-24 189
2018-11-25 76
2018-11-26 276
2018-11-27 220
2018-11-28 183
2018-11-29 251
2018-11-30 189
Name: unidades, dtype: int64
Y ahora seguiremos el mismo preprocesado de datos que hicimos para el entrenamiento: escalando los valores, llamando a la función series_to_supervised pero esta vez sin incluir la columna de salida “Y” pues es la que queremos hallar. Por eso, verán en el código que hacemos drop() de la última columna.
|
1 2 3 4 5 6 7 8 |
values = ultimosDias.values values = values.astype('float32') # normalize features values=values.reshape(-1, 1) # esto lo hacemos porque tenemos 1 sola dimension scaled = scaler.fit_transform(values) reframed = series_to_supervised(scaled, PASOS, 1) reframed.drop(reframed.columns[[7]], axis=1, inplace=True) reframed.head(7) |
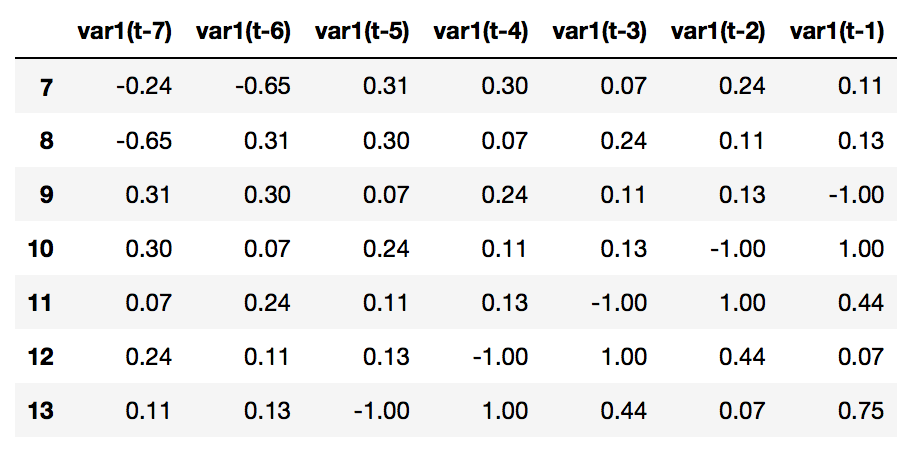
De este conjunto “ultimosDias” tomamos sólo la última fila, pues es la que correspondería a la última semana de noviembre y la dejamos en el formato correcto para la red neuronal con reshape:
|
1 2 3 4 |
values = reframed.values x_test = values[6:, :] x_test = x_test.reshape((x_test.shape[0], 1, x_test.shape[1])) x_test |
array([[[ 0.11000001, 0.13 , -1. , 1. ,
0.44000006, 0.06999993, 0.75 ]]], dtype=float32)
Ahora crearemos una función para ir “rellenando” el desplazamiento que hacemos por cada predicción. Esto es porque queremos predecir los 7 primeros días de diciembre. Entonces para el 1 de diciembre, ya tenemos el set con los últimos 7 días de noviembre. Pero para pronosticar el 2 de diciembre necesitamos los 7 días anteriores que INCLUYEN al 1 de diciembre y ese valor, lo obtenemos en nuestra predicción anterior. Y así hasta el 7 de diciembre.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def agregarNuevoValor(x_test,nuevoValor): for i in range(x_test.shape[2]-1): x_test[0][0][i] = x_test[0][0][i+1] x_test[0][0][x_test.shape[2]-1]=nuevoValor return x_test results=[] for i in range(7): parcial=model.predict(x_test) results.append(parcial[0]) print(x_test) x_test=agregarNuevoValor(x_test,parcial[0]) |
Ya casi lo tenemos… Ahora las predicciones están en el dominio del -1 al 1 y nosotros lo queremos en nuestra escala “real” de unidades vendidas. Entonces vamos a “re-transformar” los datos con el objeto “scaler” que creamos antes.
|
1 2 3 |
adimen = [x for x in results] inverted = scaler.inverse_transform(adimen) inverted |
array([[174.48904094],
[141.26934129],
[225.49292353],
[203.73262324],
[177.30941712],
[208.1552254 ],
[175.23698644]])
Ya podemos crear un nuevo DataFrame Pandas por si quisiéramos guardar un nuevo csv con el pronóstico. Y lo visualizamos.
|
1 2 3 4 |
prediccion1SemanaDiciembre = pd.DataFrame(inverted) prediccion1SemanaDiciembre.columns = ['pronostico'] prediccion1SemanaDiciembre.plot() prediccion1SemanaDiciembre.to_csv('pronostico.csv') |
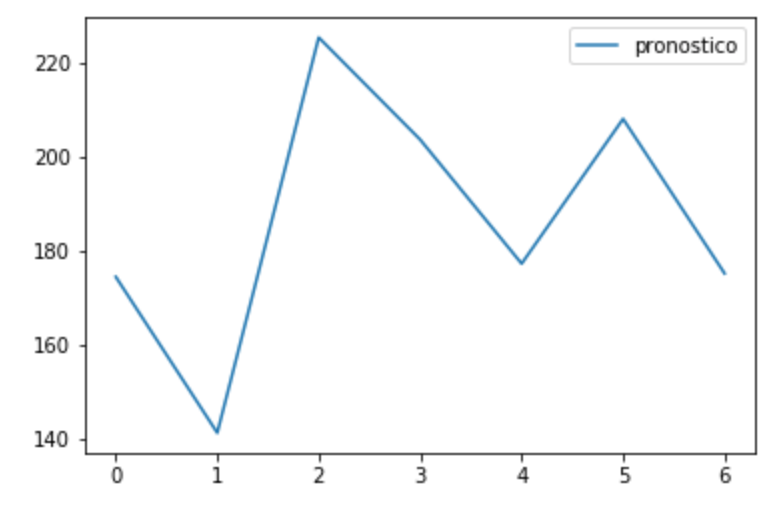
No te pierdas la Segunda Parte de este artículo sobre Pronóstico de Series Temporales con Redes Neuronales en Python: Multiples Variables y Embeddings
Conclusiones y propuesta al lector
Durante este nuevo capítulo del aprendizaje automático, diferenciamos lo que son las Series Temporales y su predicción de los problemas de Regresión. Aprovechamos la capacidad de las redes neuronales de generalizar y lograr predecir ventas futuras. Uno de los pasos más importantes, al realizar el pre procesado, consiste en convertir nuestra serie en un modelo de aprendizaje supervisado, donde tenemos valores de entrada y salida, para poder entrenar la red. Y finalizamos realizando pronóstico de una semana utilizando la red neuronal creada.
Propongo al lector hacer diversas pruebas para mejorar las predicciones, alterando parámetros del ejercicio:
- Variar la cantidad de EPOCHS
- Probar otro optimizador distinto a Adam, ó configurar valores distintos de Learning Rate.
- Cambiar la arquitectura de la Red Neuronal:
- Cambiar la cantidad de Neuronas de la capa oculta.
- Agregar más capas ocultas
- Probar utilizando más de 7 días previos para predecir. O probar con menos días.
- Se puede probar de intentar predecir más de 1 día por vez (sin iterar el resultado como hice con la función agregarNuevoValor() )
En el próximo artículo (YA DISPONIBLE) retoma este ejercicio pero aplicando Embeddings que puede mejorar la precisión de las predicciones poniendo en juego el día de la semana y mes que estamos pronosticando, considerándolos como datos adicionales de entrada a la red neuronal para preservar mejor la estacionalidad.
NOTA 1: recordemos que el futuro es IMPREDECIBLE… por lo que debo decir al Científico de datos: cuidado sobre todo si debemos predecir resultados de series con comportamiento errático, como los valores de la bolsa! y también cautela en asuntos sensibles sobretodo relacionados con la salud.
NOTA 2: Debo confesar que inicialmente implementé el ejercicio utilizando Redes Neuronales Recurrentes, de tipo LSTM pero obtuve pésimos resultados… encontré mucho mejor performante a nuestras queridas “redes neuronales tradicionales” MLP.
Unete al Blog y Recibe el próximo artículo!
Recibe los nuevos artículos sobre Machine Learning, redes neuronales y todo el código Python en tu casilla de correo!
NOTA: muchos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente a tus contactos para evitar problemas. Gracias!
Recursos del Artículo y Enlaces
- Acceder a la Jupyter Notebook con el ejercicio completo (y siempre algún Bonus Track) en Github. (Si te falla el enlace, prueba con ESTE)
- Descargar el archivo de entrada csv con la serie temporal usada en el ejercicio
- PARTE 2 – Pronóstico de Ventas con Multiples Variables y Embeddings
- Herramientas para valorar y mejorar el modelo: Interpretación de modelos de ML
Artículos recomendados en Inglés (I’m sorry)
Muy interesante!
Si, por ejemplo, quisiéramos tener en cuenta otros factores asociados, por ejemplo temperatura ambiente y cómo está está relacionada con el volumen de ventas ¿qué orientación deberíamos tomar? Aquí, por lo que veo, únicamente analizamos las ventas de helados en sí, pero no estamos haciendo un análisis multifactorial.
Hola Ivan Diaz, gracias por escribir. Te comento, en este ejercicio, es tal como tu dices de “una” variable. Pero se puede hacer pronóstico de series “multivariable”. En ese caso, deberemos tener más columnas como las llamadas var1(t-n) pero agregando por ejemplo var2(t-n), etc.
En el próximo artículo puede que escriba sobre eso mismo. Entre tanto te dejo este enlace que te resultará útil: Multivariate Time Series Forecasting
Saludos!
Buenas tardes, la consulta es si se puede hacer una serie de tiempo, con variables de entradas por ejemplo, X1, X2, X3, X4 y una variable Y1 respecto al tiempo es decir una serie temporal univariada para Y con variables de entrada X’s pero respecto al tiempo. sabe de algún tutoría o que técnicas puedo aplicar como modelos de pronostico????
De gran ayuda! Estoy iniciando en este campo para el desarrollo de mi tesis universitaria y menos mal encontre este blog tan bueno, gracias y felicidades!
Hola Cristian, gracias por tu comentario!, espero poder seguir ayudando a todos quienes se inician en Aprendizaje Automático.
¿Sobre qué será tu tesis universitaria?
Si quieres puedes suscribirte al blog para recibir los próximos artículos!
Saludos
Muy buen artículo.
Una consulta, he observado que cuando se realiza el pronostico de la primer semana de diciembre, los valores se escalan sólo considerando el valor máximo y mínimo entre estas fechas df[‘2018-11-16′:’2018-11-30’]
¿Deberían escalarse considerando el maximo y minimo de todos de los valores con los que fue entrenada la red?
Gracias
Gracias. Me pasa de entender las ideas pero no lo tengo tan claro leyendo el código. Me pareció buenisimo lo de “crear” la columna de salida para poder hacer supervisado.
Por otra parte, ¿Cómo garantizamos estacionalidad? ¿Es crucial que lo sea? Los métodos estadísticos para averiguarlo son más largos que ir probando diferentes redes neuronales. Sigo aprendiendo.
Hola Juan, Te felicito por esta buena iniciativa, actualmente estoy trabajando en mi propuesta de Tesis de Grado Universitaria y encontrar un lugar que explique de esta manera tan organizada los propósitos, usos y aplicación de Machine Learning, a sido complicado.
Mi tesis de grado es Desarrollar un servicio de predicción de ventas basado en machine learning, que pueda ser usado por todas las empresas que facturen en un Sistema de Facturación.
Te quería preguntar, basado en tu experiencia, cuanto tiempo aproximadamente conlleva elaborar un proyecto de machine learning, esta pregunta la hago ya que necesito realizar mi crono grama, pero sin la experiencia de haberlo realizado antes no se bien como
Hola Juan!
Muchas gracias por divulgar tu conocimiento!
Hace aprox un año que estoy metiendome en el mundo de la programación, data science, ML, IA, etc y este articulo es de lo mas claro y completo que me he topado.
seguiré de cerca tu blog para seguir aprendiendo, comentando y quien dice, en algun momento sumar algo!
Saludos desde Córdoba!
Genial, me alegra saber que los artículos ayudan a aprender 🙂 Espero que sigamos en contacto y espero tus comentarios y aportes!
Saludos
Hola, no me queda claro la necesidad de convertir la serie para que se calcule el valor dels el 8vo día. Si tuviera mes del año, cantidad de clientes activos en ese mes y como resultado, las cantidad de pedidos procesados en el mes, ¿No estaría bien asi para entrenar una red para predecir la cantidad de envíos, teniendo como entradas al mes y cantidad de clientes en ese mes? Muchas gracias Juan!
Hola José en este caso intentamos hacer que la red “entienda” los ciclos de estacionalidad del comercio. No siempre será igual y puede que dependiendo las ventas pasadas cambien ligeramente las predicciones. Pero ojo, no descarto tu solución y de hecho hasta ahora los pronósticos se venían haciendo con fórmulas estadísticas y no con redes neuronales! Saludos
Buenas Juan, muchas gracias por el post, pero me surge la siguiente duda en la última parte. Cuando predices el primer día de diciembre omites el últiimo día de noviembre al tener pasos = 7; para este caso no se debería incluir este último dia de noviembre tambien?.
Hola Lourdes, yo juraría que sí está incluyendo el último dia de noviembre, el 30. ¿Acaso encontraste un error? si es así te pido que me lo expliques para poder corregirlo!
Saludos y muchas gracias!!
hola despues de revisar varias veces los resultados al menos en mi caso concreto los calculos que hace para la media, la desviacion estandar e incluso para la prediccion la hace sobre el valor de dias no sobre las ventas, es decir calcula siempre sobre la primer columna no sobre la segunda que es donde tengo las ventas, tu ejemplo dice «Son un total de 604 registros, la media de venta de unidades es de 215 y un desvío de 75, es decir que por lo general estaremos entre 140 y 290 unidades.» pero eso se refiere a los dias no a las ventas del dia.. espero haberme explicado y me pudieras ayudar a entender este punto, de antemano te agradezco y te felicito por tu valioso aporte a los que recien nos iniciamos en esta materia.
Hola Ricardo, en cuanto pueda lo reviso y te escribo, si es un error mío lo cambiaré! Muchas gracias por escribir!!
Hola Ricardo, gracias nuevamente por escribir. Según veo yo, el artículo está correcto, pues mira que cuando cargamos el archivo csv con Pandas, utilizamos la columna de fecha como “indice”, entonces al hacer el df.describe() sólo tenemos en cuenta la columna de ventas, no la de los días. Por lo tanto los valores estadísticos que ves se refieren a las ventas.
Saludos!
Hola. Primero que nada Felicitaciones y gracias por tu blog. Es de mucha ayuda. Tal vez sea una pregunta muy simple de contestar pero soy nuevo en el tema. La información de salida de los Epoch como deberíamos leerla? Loss: 0.0809 es equivalente a un 8% de error? y el mean_squared_error?
Desde ya muchas gracias
Hola Wezen, no es esa relación! el 0.08 no significa el 8% error!
Realmente se refiere al valor de “loss” de la función de coste. Pero no sigue una escala comparable con alguna unidad.
Lo que tu dices de 8% error, podría ser el accuracy, es decir, si tienes un 92% de aciertos, podríamos decir que tienes un 8% de error… aunque también te diría no te fíes de esas métricas, como lo comento en el artículo Clasificación con datos desbalanceados.
Saludos
Hola Juan, como estas!! Muchas Gracias por la detallada explicación.
He leído varios artículos del blog y tengo una duda de los diferentes de algoritmos que puedo utilizar en mi proyecto de Grado, el cual consiste en predecir la cantidad de llamadas que van a ingresar a un call center. Tengo como dataset el servicio,fecha y numLlamadas de 3 años, pero no se si implementarlo con series de tiempo con redes neuronales o regresión lineal, cual es el recomendado.
De ante mano muchas Gracias por la colaboración.
A ver, en principio descartaría clasificación, con lo cual nos queda regresión. Y dentro de regresión podrías usar Time Series si hubiera estacionalidad. Para implementar el Time Series podrías usar Redes Neuronales.
Saludos!
POR FAVOR PON PARA PODER DESCARGAR EL CODIGO
Hola Angel, gracias por escribir. Puedes descargar TODO el código de todos los artículos desde mi cuenta Github. Todos los artículos tienen enlaces a la Notebook y a su correspondiente archivo CSV.
Si necesitas ayuda me dices! Saludos
Hola Juan, aún no logro encontrar en qué parte del código colocas que es solo 1 capa oculta con 7 nodos.
Si pudieras aclararme esa duda sería genial!
Saludos y gracias.
Muchas gracias, muy útil tu página para mí. Tengo una pregunta: ¿Qué tipo de método usaste para hacer una prueba de respaldo teniendo en cuenta: https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
Pregunto ya que es una serie temporal y me gustaría usar su código y la validación de mi red neuronal. Muchas gracias
Excelente ejercicio.
¿Tendrás ejemplos de predicción con series de tiempo donde se consideren valores textuales (texto) como parámetro?
Saludos y mas de estos ejercicios.
Muy practico el paso a paso pero disculpa quizás estoy haciendo algo mal pero replique todos los pasos pero no logro igualar tus valores de predicción, si bien estos valores son dinámicos pero deberían cuadrarse según la configuración…
Muchas gracias por el artículo, es de agradecer explicaciones en castellano y tan claras sobre temas de predicciones y machine learning.
Saludos.
Hola Juan, saludos desde Chile. Te cuento que hice tu ejercicio con los datos que das en el CSV pero los normalice entre 0 y 1 para probar con la función de activación sigmod. yo programo en Visual Studio 2015 y uso mysql. También fui probando en cambiar el numero de neuronas en la capa oculta. Todo va bien , logro los resultados deseados con muy poco error , claro de después de unas 100.000 vueltas jaja. Mi pregunta va por el lado de la diferencia que habría en el uso de la normalización entre -1 y 1 y la función tangente, me fue mucho mas complejo con esta función. Habrá mucha diferencia en otros tipos de casos ?
UNA CONSULTA, TENGO LA VARIABLE PRODUCCION EN TONELADA DE PALTA, Y TENGO UNA SERIE HISTORICA POR MESES DE LA PRODUCCION DE PALTA DE 20 AÑOS EN FUNCION DEL TIEMPO, ADEMAS DE ESO TENGO OTRAS VARIABLES LAS CUALES ESTAS AFECTARIAN A LA PRODUCCION, LAS CUALES TAMBIEN ESTAN AFECTAS AMARRADAS A TIEMPO, ES DECIR COMO SI TUVIERA UNA MATRIZ DE DATOS X´s y Y. MI CONSULTA ES COMO PUEDO REALIZAR EL TRAIN Y TEST PARA VALIDAR MI MODELO APLICANDO LA TECNICA DE WALK FOWARD VALIDATION.. LA CUAL CADA VE QUE VALIDA UN MODELO VA ACUMULANDO NUEVA MENTE MAS DFATA DEL TEST Y ASI SUCESIVAMENTE…. ME PODRIAN APOYAR COMO LO PODRIA HACER EN PYTHON… EH TRATADO DE HACER ESO PARA UNA SOLO VARARIABLE POR EJEMPLO SOLO LA PRODUCCION EN EL TIEMPO…… PERO CUANDO TENGO VARIAS VARIABLES K AFECTAN A LA VAR. Y, COMO PODRIA HACERLO APLICANDO WALK FOWARD VALIDATION… ADJUNTO UN LINK DE CVOMO ES LA TECNICA https://www.amibroker.com/guide/h_walkforward.html
Muchas gracias por el articulo, muy bueno. Quisiera saber como hace la gráfica de “validate loss” con la que descarta el overfitting. Gracias.
Hola Daniel, si entras en la notebook en GitHub, verás que tiene el código completo incluyendo la gráfica de Validate loss.
Saludos.
Hola como estás,excelente pagina y de mucha ayuda, cuando agrego este código me da el siguiente error, me podrías ayudar por favor?
EPOCHS=40
model = crear_modeloFF()
history=model.fit(x_train,y_train,epochs=EPOCHS,validation_data=(x_val,y_val),batch_size=PASOS)
NameError Traceback (most recent call last)
in
1 EPOCHS=40
2
—-> 3 model = crear_modeloFF()
4
5 history=model.fit(x_train,y_train,epochs=EPOCHS,validation_data=(x_val,y_val),batch_size=PASOS)
in crear_modeloFF()
1 def crear_modeloFF():
—-> 2 model = Sequential()
3 model.add(Dense(PASOS, input_shape=(1,PASOS),activation=’tanh’))
4 model.add(Flatten())
5 model.add(Dense(1, activation=’tanh’))
NameError: name ‘Sequential’ is not defined
Gracias por tus articulos, me han sido de mucha ayuda.
Una pregunta, si mi base de datos es por periodos semestrales ¿Cómo le inidico a la red que la prediccion la quiero por semestre?
Lo estoy haciendo con multiples variables. Si tuvieses algun ejemplo de la implementación con un ejemplo con lapsos semestrales en lugar de diarios sería de excelente ayuda para tomarlo como base para mi problema particular. Gracias de nuevo.
Como hago para predecir más de una variable por ejemplo tengo una serie de tiempo histórico donde tengo humedad, temperatura, precipitación!!! Puedo predecir las 3 a la vez?
Si, claro que se puede! Esa es una ventaja de las redes neuronales frente a otros algoritmos.
Saludos y gracias por comentar
Lee la segunda parte, en el ejemplo “modelo 2” tiene una notebook donde agrega la variable fecha. Deberías hacer lo mismo pero con humedad, etc.
Saludos!
Hola, Felicidades por el blog. Es muy interesante.
Me ha sorprendido tu “Nota 2”. LSTM se supone que está específicamente diseñado para este tipo de problemas, las predicciones temporales gracias a su arquitectura “simulando” memoria a corto o largo. Por qué crees que el resultado te dio peor que con una MLP?
Hola juan
muchas gracias por el articulo
una pregunta ,estoy trabajando en GOOGLE COLAB— y no me carga el archivo csv—me sale error
FileNotFoundError: [Errno 2] No such file or directory: ‘time_series.csv’
como puedo solucionarlo???
gracias
Te felicito Juan, más claro imposible, con la experiencia que tengo puedo decir que tus explicaciones son muy claras sobre todo para aquellos que están empezando en este mundo de Machine Learning. Grandioso trabajo.
Hola Elthon, muchas gracias por tus palabras, la verdad que estoy algo desanimado en lo que va de año, (por temas personales) y quiero retomar la escritura en el blog y comentarios como el tuyo me dan energía para volver a hacerlo.
Saludos!
Buenos tardes, la presente es para felicitarlo, quiero hacerle una pregunta. ¿Cómo puedo visualizar la arquitectura del modelo de RN con sus respectivos pesos sinápticos?.¿Existe la posibilidad de generarlos?. Es que estoy haciendo un modelo de series de tiempo utilizando RN y no sé cómo realizarlo.
Para ver la arquitectura con Keras tienes el método:
print(model.summary())o cómo imagen:
from keras.utils.vis_utils import plot_model
plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
Para ver los pesos de cada layer, tienes que ir iterando similar a esto:
weights, biases = model.layers[0].get_weights()
Saludos!
Muchas Gracias por la respuesta.
Felicitaciones por su trabajo muy bien explicado. Por favor quisiera que me explique porque descarta el overfitting observando la grafica de «validate loss». Muchas gracias.
Buen día. Muy buenos ejercicios son los que presentas. Soy nuevo en este ambiente de programación, pero la forma de explicar es entendible, aunque debo seguir leyendo e informándome más. Por lo mismo, tengo una duda, en base a este ejercicio, ¿cuál sería el porcentaje de «efectividad» del modelo o el equivalente al R2 de una regresión?
Muchas gracias por tu atención y felicidades!!!
Hola Eduardo, en este artículo está utilizando MAE “mean absolute error” aunque existen otras métricas de error. Al ser un problema de regresión (con series temporales) y tratarse de ventas, puede que nos interese el promedio en la cantidad de la predicción (que se falló). La parte buena es que no hay que hacer cálculos adicionales. Si el MAE es de 10, sabemos que el promedio de error en nuestra predicción será de 10 unidades de stock.
Saludos!
Estimado Juan:
Me encantó leer tu blog sobre el uso de redes neuronales artificiales en la estimación de pronósticos, sólo quedé con ganas de saber más cosas, por ejemplo, cómo poder “tunear” la red, es decir, hacer una grilla para cambiar el número de capas ocultas, el número de neuronas en esas capas, distintas épocas, etc.
Nuevamente te felicito por la buena redacción y fáciles explicaciones.
Un gran abrazo y saludo desde CHILE
Gabriel Cornejo.