
 by
by Los Transformers aparecieron como una novedosa arquitectura de Deep Learning para NLP en un paper de 2017 “Attention is all you need” que presentaba unos ingeniosos métodos para poder realizar traducción de un idioma a otro superando a las redes seq-2-seq LSTM de aquel entonces. Pero lo que no sabíamos es que este “nuevo modelo” podría ser utilizado en más campos como el de Visión Artificial, Redes Generativas, Aprendizaje por Refuerzo, Time Series y en todos ellos batir todos los records! Su impacto es tan grande que se han transformado en la nueva piedra angular del Machine Learning.
En este artículo repasaremos las piezas fundamentales que componen al Transformer y cómo una a una colaboran para conseguir tan buenos resultados. Los Transformers y su mecanismo de atención posibilitaron la aparición de los grandes modelos generadores de texto GPT2, GPT3 y BERT que ahora podían ser entrenados aprovechando el paralelismo que se alcanza mediante el uso de GPUs.
Agenda
- ¿Qué son los transformers?
- Arquitectura
- General
- Embeddings
- Positional Encoding
- Encoder
- Mecanismo de Atención
- Add & Normalisation Layer
- Feedforward Network
- Decoder
- Salida del Modelo
- Aplicaciones de los Transformers
- BERT
- GPT-2
- GPT-3
- Resumen
¿Qué son los transformers en Machine Learning?
En el paper original de 2017 “Attention is all you need” aparece el diagrama con la novedosa arquitectura del Transformer, que todos deberíamos tatuarnos en un brazo. Esta arquitectura surge como una solución a problemas de aprendizaje supervisado en Procesamiento del Lenguaje Natural, obteniendo grandes ventajas frente a los modelos utilizados en ese entonces. El transformer permitía realizar la traducción de un idioma a otro con la gran ventaja de poder entrenar al modelo en paralelo; lo que aumentaba drásticamente la velocidad y reducción del coste; y utilizando como potenciador el mecanismo de atención, que hasta ese momento no había sido explotado del todo. Veremos que en su arquitectura utiliza diversas piezas ya existentes pero que no estaban combinadas de esta manera. Además el nombre de “Todo lo que necesitas es Atención” es a la vez un tributo a los Beatles y una “bofetada” a los modelos NLP centrados en Redes Recurrentes que en ese entonces estaban intentando combinarlos con atención. De esta sutil forma les estaban diciendo… “tiren esas redes recurrentes a la basura”, porque el mecanismo de atención NO es un complemento… es EL protagonista!
All you need is
The BeatlesLoveAttention
Con el tiempo, esta arquitectura resultó ser flexible y se pudo utilizar para tareas más allá del NLP, además de para la generación de texto, clasificación, resumen de contenidos también pudo traspasar esa frontera y ser aplicado en Visión Artificial, Generación de Audio, Predicción de Series Temporales y Aprendizaje por Refuerzo.
La Arquitectura Encoder-Decoder del Transformer
Veamos primero la gran foto de los Transformers.
Visión General
Estás viendo el dibujo que deberías de llevar en tu próxima camiseta:
La primera impresión puede ser algo intimidante, pero vayamos poco a poco. Si pensamos en el modelo como una caja negra, sería simplemente:
Entrada -> Transformer -> Salida
Vemos que con una entrada de texto “Hola” obtenemos la salida “Hello”.
Si hacemos un poco de zoom en esa caja, veremos dos componentes principales: Encoders y Decoders.
La entrada pasará por una serie de Encoders que se encadenan uno tras otro y luego envían su salida a otra serie de Decoders hasta emitir la Salida final. En el paper original, se utilizan 6 encoders y 6 decoders. Notaremos un recuadro llamado “Target” donde estamos pasando el Output Deseado al modelo para entrenar; pero obviamente que no lo pasaremos al momento de la inferencia; al menos no completo (más adelante en el artículo).
Observamos ahora con mayor detalle cómo está compuesto un Encoder y un Decoder y veremos que son bastante parecidos por dentro.
En su interior tanto Encoder como decoder cuentan con un componente de Atención (o dos) y una red neuronal “normal” como salidas.
Para comenzar a evaluar con mayor detalle las partes del Transformer, primero deberemos generar un Embedding de la entrada y luego entrar al Encoder. Así que veamos eso primero.
Embeddings
El uso de embeddings existía en NLP desde antes de los Transformers, puede que estés familiarizado con modelos como el word-2-vec y puede que ya hayas visto las proyecciones creadas con miles de palabras donde los embeddings logran agrupar palabras de manera automática en un espacio multidimensional. Entonces conceptos como “hombre y mujer”, distanciado de “perro y gato” veremos nombres de países juntos y profesiones ó deportes también agrupados en ese espacio. Primero convertimos las palabras a tokens, es decir a un valor numérico asociado, porque recordemos que las redes neuronales únicamente pueden procesar números y no cadenas de texto.

Entonces convertimos una palabra a un número, ese número a un vector de embeddings de 512 dimensiones (podría ser de otro valor, pero el propuesto en el paper fue este).
Entonces:
- Palabra -> Token(*)
- Token -> Vector n-dimensional
(*) NOTA: una palabra podría convertirse en más de un token
La parte novedosa que introduce el paper de los transformers, es el “Positional Encoding” a esos embeddings…
Positional Encoding
Una vez que tenemos los embeddings, estaremos todos de acuerdo que el orden en que pasemos las palabras al modelo, será importante. De hecho podríamos alterar totalmente el significado de una oración si mezclamos el orden de sus palabras o hasta podría carecer totalmente de significado.
La casa es verde != verde casa la es
Entonces necesitamos pasar al modelo los tokens pudiendo especificar de alguna manera su posición.
Aquí, de paso comentaremos dos novedades de los Transformers: la solución a este posicionamiento pero también esto permite el poder enviar en simultáneo TODOS los tokens al modelo, algo que anteriormente no se podía hacer, por lo que se pasaba “palabra por palabra” una después de la otra, resultando en una menor velocidad.
Para resolver el posicionamiento, se agrega una valor secuencial al embedding que se asume que la red podrá interpretar. Si aparece el token “perro” como segunda palabra ó como décima, mantendrá en esencia el mismo vector (calculado anteriormente en el embedding) pero con un ligero valor adicional que lo distinguirá y que será el que le de la pista a la red neuronal de interpretar su posición en la oración.
En el paper se propone una función sinusoidal sobre el vector de 512 dimensiones del embedding. Entonces ese vector de embeddings del token “perro” será distinto si la palabra aparece primera, segunda, tercera.
Y ahora sí, podemos dar entrada al Encoder de los Transformers.
Encoder
El Encoder está compuesto por la capa de “Self attention” y esta conectada a una red feed forward. Entre las entradas y salidas se aplica la Skip Connection (ó ResNet) y un Norm Layer.
El mecanismo de Atención, es una de las implementaciones novedosas que propone el paper. Veremos que logra procesar en paralelo, manteniendo la ventaja de entreno mediante GPU.
El Encoder tiene como objetivo procesar la secuencia de los tokens de entrada y ser a su vez la entrada del mecanismo de atención del Decoder. No olvides que realmente se encadenan varios Encoders con varios Decoders (no se utilizan sólo uno en la práctica).
El -dichoso- mecanismo de Atención
Primero que nada, ¿Para qué queremos un mecanismo de Atención? El mecanismo de atención nos ayuda a crear y dar fuerza a las relaciones entre palabras en una oración. Si tenemos el siguiente enunciado:
El perro estaba en el salón, durmiendo tranquilo.
Nosotros comprendemos fácilmente que la palabra “tranquilo” se refiere al perro y no al “salón”. Pero a la red neuronal que comienza “en blanco”, sin saber nada de las estructuras del lenguaje (español, pero podría ser cualquier idioma), y que además ve la misma frase como valores numéricos:
5 186 233 7 5 1433 567 721
NOTA: no olvides que cada token, por ej. el nº5 corresponde a un embedding de n-dimensiones de 512 valores. Por simplificar usamos el 5 como reemplazo de “El”, por no escribir sus 512 componentes.
¿Cómo podrá entender que ese último token “721” está afectando a la segunda palabra “186”?
Por eso surgen los mecanismos de atención; para lograr dar más -o menos- importancia a una palabra en relación a las otras de la oración.
La solución que presentan los Transformers en cuanto a la atención, es la construcción de un “Diccionario Blando” (Soft Dictionary). ¿Qué es esto de un diccionario blando?
En programación, es probable que conozcas el uso de diccionarios de tipo “clave-valor” un típico “hashmap” en donde ante una entrada, obtengo un valor dict[“perro”]=0.78.
Para el “diccionario de atenciones” podría ser que si pedimos la atención de “tranquilo vs perro” de la oración, nos devuelva un 1 indicando mucha atención, pero si le pedimos “tranquilo vs salón” nos devuelva un -1.
Pero… eso no es todo. Nuestro Diccionario es “Suave/Blando”, esto quiere decir que no se va a saber “de memoria” el resultado de una clave. Si alteramos un poco la oración, el diccionario tradicional fallaría:
El perro estaba durmiendo en un salón tranquilo.
Ahora la clave de atención para “tranquilo vs salón” deberá pasar de -1 a ser cercana a 1.
Para poder calcular la atención, se utilizan 3 matrices llamadas “Query-Key-Value” que van a operar siguiendo una fórmula que nos devuelve un “score” o puntaje de atención.
- En la matriz Q de Query tendremos los tokens (su embedding) que estamos evaluando.
- En la matriz K de Key tendremos los tokens nuevamente, como claves del diccionario.
- En la matriz V de Value tendremos todos los tokens (su embedding) “de salida”.
El resultado de la atención será aplicar la siguiente fórmula:
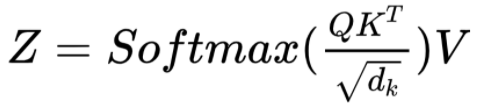
Si nos olvidamos del Softmax y el “multihead” (se definirá a continuación), podemos simplificar la fórmula diciendo que:
La atención será multiplicación matricial Q por la transpuesta de K; a eso le llamamos “factor”; y ese factor multiplicado por V.
¿Y eso qué significa? ¿Por qué estamos operando de esa manera? Si recuerdas, tanto Q como K son los valores de los Embeddings, es decir, cada token es un vector n-dimensional. Al hacer el producto vectorial obtenemos matemáticamente la “Similitud” entre los vectores. Entonces si el embedding estuviera funcionando bien, la similitud entre “nieve” y “blanco” deberían estar más cercanas que “nieve” y “negro”. Entonces cuando dos palabras sean similares, tendremos un valor positivo y mayor que si son opuestos, donde obtendríamos un valor negativo (dirección contraria). Este factor se multiplica por la matriz de Valor conformando el Score final de atención para cada relación entre pares de <<palabras>> que estamos evaluando.

Como estamos trabajando con matrices, seguimos aprovechando la capacidad de calcular todo a la vez y poder hacerlo acelerado por GPU.
Más de una atención: Multi-Head Attention
…hay más en el paper, porque el tipo de atención que vamos a calcular se llama “Multi-head Attention“. ¿Qué son esas “Multi-cabezas”??? Lo que se hace es que en vez de calcular la atención de todos los tokens de la oración una vez con las 512 dimensiones (provenientes del embedding), subdividiremos esos valores en grupos y de cada uno, calcular su atención. En el paper proponen “8 heads” con lo que entonces calcularemos “8 atenciones de a 64 valores del embeddings” por cada token! Esto a mi modo de entender es algo bastante arbitrario pero por arte de “magia matemática” funciona… Luego de calcular esas 8 cabezas, (esas 8 atenciones) haremos un promedio de los valores de cada atención entre tokens.
Si volvemos al ejemplo para la clave de “tranquilo vs perro” calcularemos 8 atenciones y al promediarlas deberíamos obtener un valor cercano a 1 (para la 1er oración).
Cuando terminemos de entrenar el modelo Transformer completo, podríamos intentar analizar y entender esas matrices de atención creadas y tratar de comprenderlas. Algunos estudios muestran que la “multi-atención” logra representar relaciones como la de “artículo-sustantivo” ó “adjetivo-sustantivo”, “verbo sustantivo” lo cual me sigue pareciendo algo increíble.
3 tipos de atención: Propia, Cruzada y Enmascarada
Prometo que esto ya es lo último que nos queda comprender sobre los mecanismos de atención… A todo lo anterior, hay que sumar que tenemos 3 tipos distintos de atención
- Self Attention
- Cross Attention
- Masked Attention
Su comportamiento es igual que al descripto anteriormente pero con alguna particularidad:
Self Attention se refiere que crearemos los valores y las matrices de Q-K-V a partir de las propias entradas de los tokens de entrada.
En la Atención Cruzada, vemos cómo utilizamos como entradas en el Decoder los valores obtenidos en el Encoder. Esto es lo que hará que con sólo el valor (Value) del Output pueda modelar la salida de atención buscada, esto es importante porque al final es lo que condicionará mayormente la “traducción” que está haciendo internamente el Decoder!
Y la llamada “Masked attention” se refiere a que enmascaramos parte triangular superior de la matriz de atención al calcularla para no caer en “data-leakage”, es decir, para no “adelantar información futura” que el Output no podría tener en su momento. Esto puede resultar confuso, intentaré aclararlo un poco más. En el Encoder, cuando tenemos los valores de entrada y hacemos “self-attention” dijimos que calculamos la atención de “todos contra todos” porque todos los tokens de entrada son conocidos desde el principio. Si recordamos la frase anterior:
El perro estaba en el salón, durmiendo tranquilo.
Aquí podemos calcular tanto la atención para la clave “perro-tranquilo” y también la de “tranquilo-perro”
Sin embargo -si suponemos que estamos traduciendo al inglés- en el output tendremos
“The dog was in the living room, sleeping peacefully”
PERO hay un detalle; para poder generar el output al momento de la inferencia, generaremos de a una palabra por vez, entonces iremos produciendo el siguiente output:
T1 – The
T2 – The dog
T3 – The dog was
T4 – The dog was in …
Esto quiere decir que vamos generando los tokens de a uno a la vez por lo que al principio no podríamos conocer la relación entre “dog-peacefully” pues esta relación aún no existe!
Entonces diferenciemos esto:
-> Al momento de entrenar el modelo pasamos el output deseado COMPLETO a las matrices de QKV de “Masked Attention” para entrenar en paralelo; al estar enmascarado, es como si estuviésemos simulando la secuencia “The, The dog, The dog was…”
-> Al momento de inferencia REALMENTE tendremos uno a uno los tokens como una secuencia temporal, realmente, iremos agregando de a una palabra del output a la cadena de salida a la vez.

Short residual skip Connections y Layer Normalization
Al utilizar Skip Connections permitimos mantener el valor de origen del input a través de las deep neural networks evitando que sus pesos se desvanezcan con el paso del tiempo. Esta técnica fue utilizada en las famosas ResNets para clasificación de imágenes y se convirtieron en bloques de construcción para redes profundas. También es sumamente importante la Normalización en RRNN. Previene que el rango de valores entre capas cambie “demasiado bruscamente” logrando hacer que el modelo entrene más rápido y con mayor capacidad de generalización.
Feed Forward Network
La salida final del Encoder la dará una Red Neuronal “normal”, también llamada MLP ó capa densa. Se agregarán dos capas con Dropout y una función de activación no lineal.
Decoder
Ahora que conocemos los componentes del Encoder, podemos ver que con esos mismos bloques podemos crear el Decoder.
Al momento de entrenar, estaremos pasando el Input “hola amigos” y Output “hello friends” (su traducción) al mismo tiempo al modelo.
Tradicionalmente, usamos la salida únicamente para “validar” el modelo y ajustar los pesos de la red neuronal (durante el backpropagation). Sin embargo en el Transformer estamos usando la salida “hello friends” como parte del aprendizaje que realiza el modelo.
Entonces, el output “hello friends” es también la “entrada” del decoder hacia embeddings, posicionamiento y finalmente ingreso a la Masked Self Attention que comentamos antes (para los valores de Q,K,V).
De aquí, y pasando por la Skip Connection y Normalización (en la gráfica “Add & Norm) entramos al segundo mecanismo de Atención Cruzada que contiene para las matrices Query y Key” la salida del Encoder y como Value la salida de la Masked Attention.
Nuevamente Suma y Normalización, entrada a la Feed Forward del Decoder.
RECORDAR: “N encoder y N decoders”
No olvidemos que si bien estamos viendo en mayor detalle “un encoder” y “un decoder”, la arquitectura completa del Transformer implica la creación de (en el paper original) 6 encoders encadenados que enlazan con otros 6 decoders.
Salida final del Modelo
La salida final del modelo pasa por una última capa Lineal y aplicar Softmax. El Softmax, por si no lo recuerdas nos dará un valor de entre 0 y 1 para cada una de las posibles palabras (tokens) de salida. Entonces si nuestro “lenguaje” total es de 50.000 posibles tokens (incluyendo signos de puntuación, admiración, interrogación), encontraremos a uno de ellos con valor más alto, que será la predicción.
Si yo te dijera “en casa de herrero cuchillo de …” y vos tuvieras que predecir la próxima palabra, de entre todas las posibles en el castellano seguramente elegirías “palo” con probabilidad 0,999. Ahí acabas de aplicar Softmax intuitivamente en tu cabeza, y descartaste al resto de 49.999 palabras restantes.
Repaso de la arquitectura
Repasemos los puntos fuertes de la arquitectura de los Transformers:
- La arquitectura de Transformers utiliza Encoders y Decoders
- El Transformer permite entrenar en paralelo y aprovechar el GPU
- Utiliza un mecanismo de atención que cruza en memoria “todos contra todos los tokens” y obtiene un score. Los modelos anteriores como LSTM no podían memorizar textos largos ni correr en paralelo.
- El mecanismo de atención puede ser de Self Attention en el Encoder, Cross Attention ó Masked Attention en el Decoder. Su funcionamiento es igual en todos los casos, pero cambian los vectores que utilizamos como entradas para Q,K,V.
- Se utiliza El Input pero también la Salida (el Output del dataset) para entrenar al modelo.
Aplicaciones de los Transformers
Los Transformers se convirtieron en el modelo “de facto” para todo tipo de tareas de NLP, incluyendo Traducción de idiomas (como vimos), clasificación de texto, resumen de textos y Question-Answering. Sólo basta con modificar los datasets que utilizamos para entrenar al modelo y la “salida final del modelo”, manteniendo al resto de arquitectura.
A raíz de poder entrenar mediante GPU, reducción de tiempo y dinero, surgieron varios modelos para NLP que fueron entrenados con datasets cada vez más grandes, con la creencia de que cuantas más palabras, más acertado sería el modelo, llevándolos al límite. Ahora, parece que hemos alcanzado un tope de acuracy, en el cual no vale la pena seguir extendiendo el vocabulario.

Vemos 3 de estos grandes modelos de NLP y sus características
BERT – 2018
BERT (Bidirectional Encoder Representations from Transformers) aparece en 2018, desarrollado por Google y utiliza sólo la parte del Encoder de los Transformers. Este modelo fue entrenado con todos los artículos de la Wikipedia en Inglés que contiene más de 2500 millones de palabras. Esto permitió generar un modelo “pro-entrenado” en inglés muy poderoso que podía ser utilizado para múltiples tareas de NLP. Además, al ser Open Source, permitió la colaboración y extensión por parte de la comunidad científica. El poder utilizar un modelo pre-entrenado tan grande, preciso y potente, permite justamente “reutilizar” ese conocimiento sin necesidad de tener que entrenar nuevamente un modelo de NLP, con el coste y tiempo (e impacto medioambiental) que puede conllevar.
Además BERT contenía algunas novedades, por ejemplo, en vez de utilizar un “Embeddings único y estático”, implementó un mecanismo en donde la misma palabra (token) podría devolver un vector distinto (de “embeddings”) de acuerdo al contexto de la oración de esa palabra.
Cuando salió BERT, batió muchos de los records existentes en datasets como SQuAD, GLUE y MultiNLI.
GPT-2 – 2019
GPT es un modelo de generación de texto creado por Open AI en 2019 y que contiene 1500 millones de parámetros en la configuración de su red neuronal profunda.
Al ser entrenado para generar “siguiente palabra”, pasa a convertirse en un problema de tipo “no supervisado”. Su re-entreno fue realizado usando BooksCorpus, un dataset que contiene más de 7,000 libros de ficción no publicados de diversos géneros.
Este modelo generó polémica en su momento debido a que empezaba a crear textos similares a lo que podía escribir una persona, con lo cual antes de ser lanzado, se temió por su mal uso para generar contenido falso en internet. Había sido anunciado en febrero y recién fue accesible al público, de manera parcial en Agosto. Los modelos de tipo GPT utilizan únicamente la parte de “Decoder” del Transformer.
Ejercicio Práctico: Crea tu propio chatbot con GPT-2 en Español!
GPT-3 – 2020
Lanzado en 2020, la red de GPT-3 tiene 175.000 millones de parámetros. Entrenado con textos de internet que contienen más de 500.000 millones de tokens.
En GPT-3, la generación de textos por la IA puede alcanzar un nivel literario que pasa inadvertido por los humanos, el modelo es capaz de mantener la coherencia en textos largos y debido a su gran conocimiento del mundo, crear un contexto y párrafos muy reales.
Otra de las novedades que trajo GPT3 es que lograba realizar tareas “inesperadas” de manera correcta, sin haber sido entrenado para ello. Por ejemplo, puede realizar Question-Answer, crear diálogos ó hasta escribir código en Python, Java o traducir idiomas. A este tipo de aprendizaje “no buscado” le llamamos “One Shot Learning”.
El Codigo de GPT-3 aún no ha sido liberado, hasta la fecha.
Más allá del NLP
Al comportarse tan bien para tareas de NLP, se comenzó a utilizar esta arquitectura adaptada para Clasificación de imágenes en Computer Vision y también logró superar en muchos casos a las Redes Convolucionales! A este nuevo modelo se le conoce como Vision Transformer o “Vit”.
También podemos utilizar Transformers para pronóstico de Series Temporales (Time Series). Este caso de uso tiene mucha lógica si lo pensamos, porque al final es muy parecido a “predecir la próxima palabra”, pero en su lugar “predecir la próxima venta”, ó stock…
Los Transformers están siendo utilizados en modelos generativos de música o como parte de los modelos de difusión text-to-image como Dall-E2 y Stable Diffusion.
Por último, los Transformers también están siendo utilizados en Aprendizaje por Refuerzo, donde también tienen sentido, pues la fórmula principal de este tipo de problemas también contiene una variable temporal/secuencial.
Y en todos estos campos, recién está empezando la revolución! No digo que será el Transformer quien reemplace al resto de Arquitecturas y modelos de Machine Learning existentes, pero está siendo un buen motivo para cuestionarlos, replantearlos y mejorar!
Resumen
Los Transformers aparecieron en un paper de 2017 implementando un eficiente mecanismo de atención como punto clave para resolver problemas de traducción en el campo del Procesamiento del Lenguaje Natural. Como bien sabemos, el lenguaje escrito conlleva implícitamente un orden temporal, secuencial que hasta aquel entonces era una de las barreras para no poder crear modelos extensos, pues impedía el aprovechamiento de GPU. La nueva arquitectura rompía esa barrera utilizando unos sencillos trucos: utilizar todos los token al mismo tiempo (en vez de uno en uno) y enmascarar la multiplicación matricial para impedir el data leakage en el caso del decoder.
Además, resolvió el Posicionamiento de los token y aprovechó técnicas ya existentes como el uso de Skip Connections y Normalization Layers.
Todo ello posibilitó la creación de los grandes modelos actuales, BERT, GPT y la aparición de muchísimos modelos disponibles “pre-entrenados” que pueden ser descargados y reutilizados para fine-tuning por cualquier persona.
Como si esto fuera poco, los Transformers tienen la flexibilidad suficiente para traspasar el área de NLP y contribuir al resto de áreas del Machine Learning obteniendo resultados impresionantes.
Habrá que agradecer a Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin por su obra maestra.
Material Extra
Enlaces a más info sobre Transformers!
- How to code Transformers
- How Transformers Work
- Understanding Transformers
- NUEVO: articulo del blog en Español: Ejercicio Python Generación de texto con GPT-2
Suscripción al Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente info @ aprendemachinelearning.com a tus contactos para evitar problemas. Gracias!
El libro del Blog
Si te gustan los contenidos del blog y quieres darme tu apoyo, puedes comprar el libro en papel, ó en digital (también lo puede descargar gratis!).



Voy a referenciar tu artículo que me parece interesantísimo.