
Arquitecturas y Aplicaciones de las Redes Neuronales más usadas.
Vamos a hacer un repaso por las diversas estructuras inventadas, mejoradas y utilizadas a lo largo de la historia para crear redes neuronales y sacar el mayor potencial al Deep Learning para resolver toda clase de problemas de regresión y clasificación.

Evolución de las Redes Neuronales en Ciencias de la Computación
Vamos a revisar las siguientes redes/arquitecturas:
- 1958 – Perceptron
- 1965 – Multilayer Perceptron
- 1980’s
- Neuronas Sigmoidales
- Redes Feedforward
- Backpropagation
- 1989 – Convolutional neural networks (CNN) / Recurent neural networks (RNN)
- 1997 – Long short term memory (LSTM)
- 2006 – Deep Belief Networks (DBN): Nace deep learning
- Restricted Boltzmann Machine
- Encoder / Decoder = Auto-encoder
- 2014 – Generative Adversarial Networks (GAN)
Si bien esta lista no es exhaustiva y no se abarcan todos los modelos creados desde los años 50, he recopilado las que fueron -a mi parecer- las redes y tecnologías más importantes desarrolladas para llegar al punto en que estamos hoy: el Aprendizaje Profundo.
El inicio de todo: la neurona artificial
1958 – Perceptron
Entre las décadas de 1950 y 1960 el científico Frank Rosenblatt, inspirado en el trabajo de Warren McCulloch y Walter Pitts creó el Perceptron, la unidad desde donde nacería y se potenciarían las redes neuronales artificiales.
Un perceptron toma varias entradas binarias x1, x2, etc y produce una sóla salida binaria. Para calcular la salida, Rosenblatt introduce el concepto de “pesos” w1, w2, etc, un número real que expresa la importancia de la respectiva entrada con la salida. La salida de la neurona será 1 o 0 si la suma de la multiplicación de pesos por entradas es mayor o menor a un determinado umbral.
Sus principales usos son decisiones binarias sencillas, o para crear funciones lógicas como OR, AND.
1965 – Multilayer Perceptron
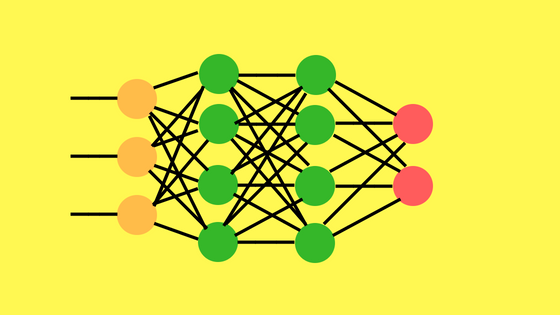
Como se imaginarán, el multilayer perceptron es una “amplicación” del percepción de una única neurona a más de una. Además aparece el concepto de capas de entrada, oculta y salida. Pero con valores de entrada y salida binarios. No olvidemos que tanto el valor de los pesos como el de umbral de cada neurona lo asignaba manualmente el científico. Cuantos más perceptrones en las capas, mucho más difícil conseguir los pesos para obtener salidas deseadas.
Los 1980s: aprendizaje automático
Neuronas Sigmoides
Para poder lograr que las redes de neuronas aprendieran solas fue necesario introducir un nuevo tipo de neuronas. Las llamadas Neuronas Sigmoides son similares al perceptron, pero permiten que las entradas, en vez de ser ceros o unos, puedan tener valores reales como 0,5 ó 0,377 ó lo que sea. También aparecen las neuronas “bias” que siempre suman 1 en las diversas capas para resolver ciertas situaciones. Ahora las salidas en vez de ser 0 ó 1, será d(w . x + b) donde d será la función sigmoide definida como d(z) = 1/( 1 +e-z). Esta es la primer función de activación!
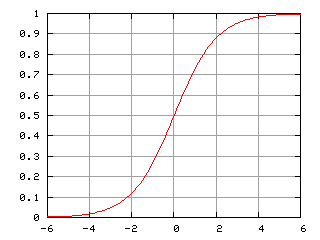
Imagen de la Curva Logística Normalizada de Wikipedia
Con esta nueva fórmula, se puede lograr que pequeñas alteraciones en valores de los pesos (deltas) produzcan pequeñas alteraciones en la salida. Por lo tanto, podemos ir ajustando muy de a poco los pesos de las conexiones e ir obteniendo las salidas deseadas.
Redes Feedforward
Se les llama así a las redes en que las salidas de una capa son utilizadas como entradas en la próxima capa. Esto quiere decir que no hay loops “hacia atrás”. Siempre se “alimenta” de valores hacia adelante. Hay redes que veremos más adelante en las que sí que existen esos loops (Recurrent Neural Networks).
Además existe el concepto de “fully connected Feedforward Networks” y se refiere a que todas las neuronas de entrada, están conectadas con todas las neuronas de la siguiente capa.
1986 – Backpropagation
Gracias al algoritmo de backpropagation se hizo posible entrenar redes neuronales de multiples capas de manera supervisada. Al calcular el error obtenido en la salida e ir propagando hacia las capas anteriores se van haciendo ajustes pequeños (minimizando costo) en cada iteración para lograr que la red aprenda consiguiendo que la red pueda -por ejemplo- clasificar las entradas correctamente.
Nuevo Artículo: Pronóstico de Series Temporales con Redes Neuronales
1989 – Convolutional Neural Network
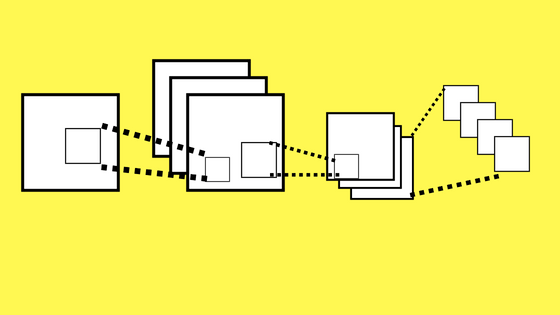
Las Convolutional Neural Networks son redes multilayered que toman su inspiración del cortex visual de los animales. Esta arquitectura es útil en varias aplicaciones, principalmente procesamiento de imágenes. La primera CNN fue creada por Yann LeCun y estaba enfocada en el reconocimiento de letras manuscritas.
La arquitectura constaba de varias capas que implementaban la extracción de características y luego clasificar. La imagen se divide en campos receptivos que alimentan una capa convolutional que extrae features de la imagen de entrada (Por ejemplo, detectar lineas verticales, vértices, etc). El siguiente paso es pooling que reduce la dimensionalidad de las features extraídas manteniendo la información más importante. Luego se hace una nueva convolución y otro pooling que alimenta una red feedforward multicapa. La salida final de la red es un grupo de nodos que clasifican el resultado, por ejemplo un nodo para cada número del 0 al 9 (es decir, 10 nodos, se “activan” de a uno).
Nuevo artículo: ¿Qué son y cómo funcionan las Convolutional Neural Networks?
Esta arquitectura usando capas profundas y la clasificación de salida abrieron un mundo nuevo de posibilidades en las redes neuronales. Las CNN se usan también en reconocimiento de video y tareas de Procesamiento del Lenguaje natural. ¿Quieres hacer tu propia CNN en Python?
1997 Long Short Term Memory / Recurrent Neural Network
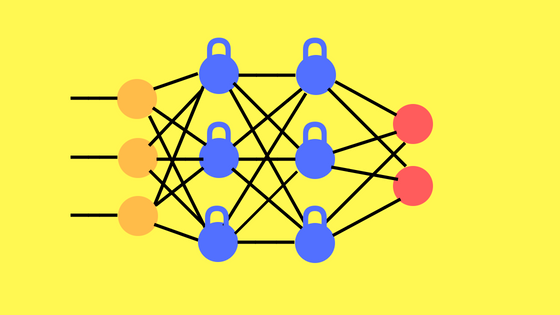
Aqui vemos que la red LSTM tiene neuronas ocultas con loops hacia atrás (en azul). Esto permite que almacene información en celdas de memoria.
Las Long short term memory son un tipo de Recurrent neural network. Esta arquitectura permite conexiones “hacia atrás” entre las capas. Esto las hace buenas para procesar datos de tipo “time series” (datos históricos). En 1997 se crearon las LSTM que consisten en unas celdas de memoria que permiten a la red recordar valores por períodos cortos o largos.
Una celda de memoria contiene compuertas que administran como la información fluye dentro o fuera. La puerta de entrada controla cuando puede entran nueva información en la memoria. La puerta de “olvido” controla cuanto tiempo existe y se retiene esa información. La puerta de salida controla cuando la información en la celda es usada como salida de la celda. La celda contiene pesos que controlan cada compuerta. El algoritmo de entrenamiento -conocido como backpropagation-through-time optimiza estos pesos basado en el error de resultado.
Las LSTM se han aplicado en reconocimiento de voz, de escritura, text-to-speech y otras tareas.
Se alcanza el Deep Learning
2006 – Deep Belief Networks (DBN)
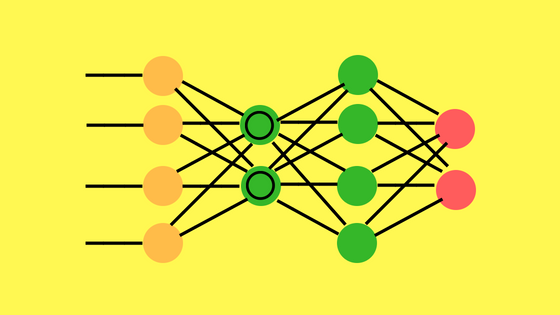
La Deep Belief Network utiliza un Autoencoder con Restricted Boltzmann Machines para preentrenar a las neuronas de la red y obtener un mejor resultado final.
Antes de las DBN en 2006 los modelos con “profundidad” (decenas o cientos de capas) eran considerados demasiado difíciles de entrenar (incluso con backpropagation) y el uso de las redes neuronales artificiales quedó estancado. Con la creación de una DBN que logro obtener un mejor resultado en el MNIST, se devolvió el entusiasmo en poder lograr el aprendizaje profundo en redes neuronales. Hoy en día las DBN no se utilizan demasiado, pero fueron un gran hito en la historia en el desarrollo del deep learning y permitieron seguir la exploración para mejorar las redes existentes CNN, LSTM, etc.
Las Deep Belief Networks, demostraron que utilizar pesos aleatorios al inicializar las redes son una mala idea: por ejemplo al utilizar Backpropagation con Descenso por gradiente muchas veces se caía en mínimos locales, sin lograr optimizar los pesos. Mejor será utilizar una asignación de pesos inteligente mediante un preentrenamiento de las capas de la red -en inglés “pretrain”-. Se basa en el uso de la utilización de Restricted Boltzmann Machines y Autoencoders para pre-entrenar la red de manera no supervisada. Ojo! luego de pre-entrenar y asignar esos pesos iniciales, deberemos entrenar la red por de forma habitual, supervisada (por ejemplo con backpropagation).
Se cree que ese preentrenamiento es una de las causas de la gran mejora en las redes neuronales y permitir el deep learning: pues para asignar los valores se evalúa capa a capa, de a una, y no “sufre” de cierto sesgo que causa el backpropagation, al entrenar a todas las capas en simultáneo.
2014 – Generative Adversarial Networks
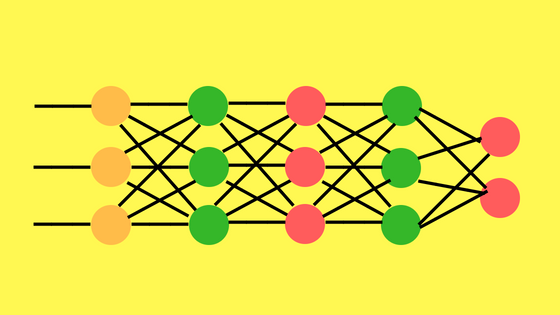
Las GAN, entrenan dos redes neuronales en simultáneo. La red de Generación y la red de Discriminación. A medida que la máquina aprende, comienza a crear muestras que son indistinguibles de los datos reales.
Estas redes pueden aprender a crear muestras, de manera similar a los datos con las que las alimentamos.
La idea detrás de GAN es la de tener dos modelos de redes neuronales compitiendo. Uno, llamado Generador, toma inicialmente “datos basura” como entrada y genera muestras. El otro modelo, llamado Discriminador, recibe a la vez muestras del Generador y del conjunto de entrenamiento (real) y deberá ser capaz de diferenciar entre las dos fuentes. Estas dos redes juegan una partida continua donde el Generador aprende a producir muestras más realistas y el Discriminador aprende a distinguir entre datos reales y muestras artificiales. Estas redes son entrenadas simultáneamente para finalmente lograr que los datos generados no puedan detectarse de datos reales.
Sus aplicaciones principales son la de generación de imágenes realistas, pero también la de mejorar imágenes ya existentes, o generar textos (captions) en imágenes, o generar textos siguiendo un estilo determinado y hasta desarrollo de moléculas para industria farmacéutica.
Conclusión, repaso y Nuevos descubrimientos
Hemos recorrido estos primeros -casi- 80 años de avances en las redes neuronales en la historia de la inteligencia artificial. Se suele dividir en 3 etapas, del 40 al 70 en donde se pasó del asombro de estos nuevos modelos hasta el escepticismo, el retorno de un invierno de 10 años cuando en los ochentas surgen mejoras en mecanismos y maneras de entrenar las redes (backpropagation) y se alcanza una meseta en la que no se puede alcanzar la “profundidad” de aprendizaje seguramente también por falta de poder de cómputo. Y una tercer etapa a partir de 2006 en la que se logra superar esa barrera y aprovechando el poder de las GPU y nuevas ideas se logra entrenar cientos de capas jerárquicas que conforman y potencian el Deep Learning y dan una capacidad casi ilimitada a estas redes.
Como último comentario, me gustaría decir que recientemente (feb 2018) hay nuevos estudios de las neuronas humanas biológicas en las que se está redescubriendo su funcionamiento y se está produciendo una nueva revolución, pues parece que es totalmente distinto a lo que hasta hoy conocíamos. Esto puede ser el principio de una nueva etapa totalmente nueva y seguramente mejor del Aprendizaje Profundo, el Machine Learning y la Inteligencia Artificial.
Suscripción al Blog
Recibe nuevos artículos sobre Machine Learning, redes neuronales y código Python cada 15 días
Más recursos / Seguir leyendo.
- ¿Qué son y cómo funcionan las Redes Neuronales Convolutionales?
- Cheat Sheets for AI
- Neural Networks and Deep Learning
- From Perceptrons to deep networks
- Neural Networks Achitectures
- A beginners guide to Machine Learning
- A guide on Time Series Prediction using LSTM
- Convolutional Neural Networks in Python with Keras
- History of Neural Network
¡Hola Juan!
Hace poco te buscaba no te encontraba… resulta que voy a empezar una asignatura de inteligencia artificial en la universidad… ya te iré informando de los avances y te preguntaré dudas… que veo que eres un crack.
¡Un abrazo amigo!
Hola David! gracias por escribirme! Me está costando conseguir huecos para ponerme a escribir, pero me encanta la IA !!!
Me parece genial que tengas IA de asignatura! espero poder ayudarte! Seguimos en contacto!
Abrazo
Gracias por la breve pero muy interesante historia!
Hola Javier, de nada! me alegro que te haya interesado! Esperemos que esta historia continue!! Saludos
Hola Juan. Encontré ru blog y lo estoy leyendo. Es muy interesante la IA. Me dedico a la Lingüística y estoy estudiando sobre Procesamiento de Lenguaje Naturtal. Estoy trabajando con Python y NLTK, aún principiante.
Hola, muchas gracias por escribir y por tu comentario! Espero que sigas estudiando, realmente trabajar con IA es super interesante!
El área de NLP es increíble con muchísimas nuevas técnicas revolucionarias.
Un saludo!