
Las principales causas al obtener malos resultados en Machine Learning son el overfitting o el underfitting de los datos. Cuando entrenamos nuestro modelo intentamos “hacer encajar” -fit en inglés- los datos de entrada entre ellos y con la salida. Tal vez se pueda traducir overfitting como “sobreajuste” y underfitting como “subajuste” y hacen referencia al fallo de nuestro modelo al generalizar -encajar- el conocimiento que pretendemos que adquieran. Lo explicaré a continuación con un ejemplo.

Generalización del Conocimiento
Como si se tratase de un ser humano, las máquinas de aprendizaje deberán ser capaces de generalizar conceptos. Supongamos que vemos un perro Labrador por primera vez en la vida y nos dicen “eso es un perro”. Luego nos enseñan un Caniche y nos preguntan: ¿eso es un perro? Diremos “No”, pues no se parece en nada a lo que aprendimos anteriormente. Ahora imaginemos que nuestro tutor nos muestra un libro con fotos de 10 razas de perros distintas. Cuando veamos una raza de perro que desconocíamos seguramente seremos capaces de reconocer al cuadrúpedo canino al tiempo de poder discernir en que un gato no es un perro, aunque sea peludo y tenga 4 patas.
Cuando entrenamos nuestros modelos computacionales con un conjunto de datos de entrada estamos haciendo que el algoritmo sea capaz de generalizar un concepto para que al consultarle por un nuevo conjunto de datos desconocido éste sea capaz de sintetizarlo, comprenderlo y devolvernos un resultado fiable dada su capacidad de generalización.
El problema de la Máquina al Generalizar
Si nuestros datos de entrenamiento son muy pocos nuestra máquina no será capaz de generalizar el conocimiento y estará incurriendo en underfitting. Este es el caso en el que le enseñamos sólo una raza de perros y pretendemos que pueda reconocer a otras 10 razas de perros distintas. El algoritmo no será capaz de darnos un resultado bueno por falta de “materia prima” para hacer sólido su conocimiento. También es ejemplo de “subajuste” cuando la máquina reconoce todo lo que “ve” como un perro, tanto una foto de un gato o un coche.
Por el contrario, si entrenamos a nuestra máquina con 10 razas de perros sólo de color marrón de manera rigurosa y luego enseñamos una foto de un perro blanco, nuestro modelo no podrá reconocerlo cómo perro por no cumplir exactamente con las características que aprendió (el color forzosamente debía ser marrón). Aquí se trata de un problema de overfitting.
Tanto el problema del ajuste “por debajo” como “por encima” de los datos son malos porque no permiten que nuestra máquina generalice el conocimiento y no nos darán buenas predicciones (o clasificación, o agrupación, etc.)
Overfitting en Machine Learning
Es muy común que al comenzar a aprender machine learning caigamos en el problema del Overfitting. Lo que ocurrirá es que nuestra máquina sólo se ajustará a aprender los casos particulares que le enseñamos y será incapaz de reconocer nuevos datos de entrada. En nuestro conjunto de datos de entrada muchas veces introducimos muestras atípicas (ó anomalas) o con “ruido/distorción” en alguna de sus dimensiones, o muestras que pueden no ser del todo representativas. Cuando “sobre-entrenamos” nuestro modelo y caemos en el overfitting, nuestro algoritmo estará considerando como válidos sólo los datos idénticos a los de nuestro conjunto de entrenamiento –incluidos sus defectos– y siendo incapaz de distinguir entradas buenas como fiables si se salen un poco de los rangos ya prestablecidos.
El equilibrio del Aprendizaje
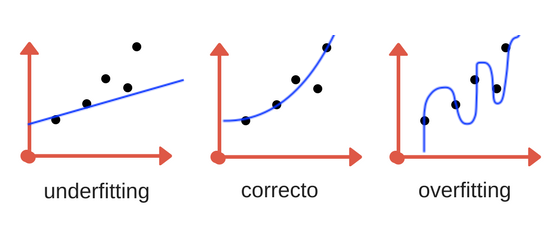
Deberemos encontrar un punto medio en el aprendizaje de nuestro modelo en el que no estemos incurriendo en underfitting y tampoco en overfitting. A veces esto puede resultar una tarea muy difícil.
Para reconocer este problema deberemos subvididir nuestro conjunto de datos de entrada para entrenamiento en dos: uno para entrenamiento y otro para la Test que el modelo no conocerá de antemano. Esta división se suele hacer del 80% para entrenar y 20%. El conjunto de Test deberá tener muestras diversas en lo posible y una cantidad de muestras suficiente para poder comprobar los resultados una vez entrenado el modelo.

Cuando entrenamos nuestro modelo solemos parametrizar y limitar el algoritmo, por ejemplo la cantidad de iteraciones que tendrá o un valor de “tasa de aprendizaje” (learning-rate) por iteración y muchos otros. Para lograr que nuestro modelo dé buenos resultados iremos revisando y contrastando nuestro entrenamiento con el conjunto de Test y su tasa de errores, utilizando más o menos iteraciones, etc. hasta dar con buenas predicciones y sin tener los problemas de over-under-fitting.
Prevenir el Sobreajuste de datos
Para intentar que estos problemas nos afecten lo menos posible, podemos llevar a cabo diversas acciones.
- Cantidad mínima de muestras tanto para entrenar el modelo como para validarlo.
- Clases variadas y equilibradas en cantidad: En caso de aprendizaje supervisado y suponiendo que tenemos que clasificar diversas clases o categorías, es importante que los datos de entrenamiento estén balanceados. Supongamos que tenemos que diferenciar entre manzanas, peras y bananas, debemos tener muchas fotos de las 3 frutas y en cantidades similares. Si tenemos muy pocas fotos de peras, esto afectará en el aprendizaje de nuestro algoritmo para identificar esa fruta.
- Conjunto de Test de datos. Siempre subdividir nuestro conjunto de datos y mantener una porción del mismo “oculto” a nuestra máquina entrenada. Esto nos permitirá obtener una valoración de aciertos/fallos real del modelo y también nos permitirá detectar fácilmente efectos del overfitting /underfitting.
- Parameter Tunning o Ajuste de Parámetros: deberemos experimentar sobre todo dando más/menos “tiempo/iteraciones” al entrenamiento y su aprendizaje hasta encontrar el equilibrio.
- Cantidad excesiva de Dimensiones (features), con muchas variantes distintas, sin suficientes muestras. A veces conviene eliminar o reducir la cantidad de características que utilizaremos para entrenar el modelo. Una herramienta útil para hacerlo es PCA.
- Quiero notar que si nuestro modelo es una red neuronal artificial –deep learning-, podemos caer en overfitting si usamos capas ocultas en exceso, ya que haríamos que el modelo memorice las posibles salidas, en vez de ser flexible y adecuar las activaciones a las entradas nuevas.
Si el modelo entrenado con el conjunto de train tiene un 90% de aciertos y con el conjunto de test tiene un porcentaje muy bajo, esto señala claramente un problema de overfitting.
Si en el conjunto de Test sólo se acierta un tipo de clase (por ejemplo “peras”) o el único resultado que se obtiene es siempre el mismo valor será que se produjo un problema de underfitting.
¿Como puedo balancear mi dataset? en este artículo te lo explico!
En Resumen
Siempre que creamos una máquina de aprendizaje deberemos tener en cuenta que pueden caer en uno de estos problemas por no poder generalizar correctamente el conocimiento. Underfitting indicará la imposibilidad de identificar o de obtener resultados correctos por carecer de suficientes muestras de entrenamiento o un entrenamiento muy pobre. Overfitting indicará un aprendizaje “excesivo” del conjunto de datos de entrenamiento haciendo que nuestro modelo únicamente pueda producir unos resultados singulares y con la imposibilidad de comprender nuevos datos de entrada.
¿Qué experiencia tienen ustedes frente a problemas de este tipo? Dejen sus comentarios y muchas gracias!
Comienza a programar en Python siguiendo los ejercicios de la Práctica – Nuevo: Regresión Lineal , k-Nearest Neighbor y una sencilla Red Neuronal
Recuerden que pueden ayudarme a difundir los artículos compartiendo el enlace en redes sociales y también están invitados a Inscribirse en el Blog para recibir las novedades cada 15 días.
Suscribe al Blog
Aprende Machine Learning te avisa del próximo artículo semanal/quincenal sobre Aprendizaje Automático.
Muy buena publicación. Muchas gracias y saludos!
Hola manuel, Muchas gracias, sigamos en contacto, saludos.
Muy bueno tu blog, gracias.
Hola, muchas gracias por escribir y participar! eso me ayuda mucho, saludos y espero verte pronto por aquí.
Muy buena y clara explicación. Muchisimas gracias!
Hola Carol, muchas gracias por tu comentario, espero tener nuevos artículos pronto! Saludos
Llevo dos semanas leyendo y viendo vídeos y hasta que no he caído aquí de casualidad, las piezas no han empezado a encajar en mi cabeza con una facilidad insultante. Está todo tan bien explicado que pienso que los artículos te los escribe un algoritmo entrenado.
Hola Daniel!, debo decirte que tu comentario debe ser el más divertido que he recibido nunca! Muchas gracias, me alegra mucho ayudar a Encajar las piezas en tu cabeza. Es algo que nos suele pasar mucho: tener muchos conceptos, todos medio desordenados dando vueltas hasta que ALGO nos hace clic e interconectamos todo para que tenga sentido!
Gracias Ignacio por sus entradas, me han enseñado bastante. Con respecto al overfitting, ¿es suficiente tomar hasta un 80% para entranar o se debería tomar un porcentaje menor? Por otro lado, ¿cuál cree usted que debe ser la mejor métrica para evaluar un modelo de regresión general con redes neuronales, una mae o mse es suficiente? De nuevo muchas gracias por su blog!
Hola Luis, muchas gracias por participar del Blog!, disculpa la tardanza en responder. Te comento que lo de subdividir en sets de entrenamiento y validación en 80-20 es una proporción bastante “estándar” para usar, pero no es obligatorio. Se pueden variar esos valores. Si contamos con un conjunto de datos muy-MUY-grande, podremos “achicar” esa proporción. Digamos que tendremos que tener muestras suficientes tanto para entrenar el algoritmo (y poder generalizar el conocimiento) como para poder validarlo, teniendo muchos casos, de lo más variados para confirmar el correcto aprendizaje.
En cuanto a la métrica para evaluar modelos de regresión, es cierto que se suele usar MSE pero nuevamente esto no es a rajatabla, por el contrario, para cada caso “en el mundo real” deberíamos encontrar la función que mejor refleje y optimice nuestro algoritmo. Intentaré escribir más sobre este tema en el futuro. Saludos
Muy bueno el artículo. El tema es cómo saber si está sobre o sub entrenado el modelo. Yo veo el error en el entrenamiento que debe ser menor que para el conjunto de prueba, pero no muuucho menor. Tengo que repasar unas explicaciones de unos métodos de Andrew Ng que trataba el tema. Saludos y confieso que de a poco se me van conectando tantas ideas que leí desordenadamente. Saludos
Me surge una duda ya que estoy viendo diferentes versiones sobre algo que dices, cuando te refieres a conjunto de validación en realidad no deberíamos de decir conjunto de test?
Hasta donde he leído yo, por ejemplo en el libro de http://www-bcf.usc.edu/~gareth/ISL/ An Introduction to Statistical Learning de Robert Tibshirani la primera división de los datos, que como bien dices es frecuente hacerla a un 80/20, se suelen denominar entrenamiento y test. Luego el conjunto de entrenamiento a si vez se suele dividir en splits o particiones al realizar métodos de validación cruzada para entrenar el modelo y ajustar los parámetros libres. En este proceso el conjunto de entrenamiento se divide a su vez en particiones de entrenamiento y validación.
Es decir, que quedaría el conjunto de entrenamiento/validación (80% normalmente pero puede variar) y luego el conjunto de test sobre el que se comprueban las prestaciones finales del modelo.
Hola speletero, puede que tenga que revisar en posts antiguos, pero lo correcto es lo que dices: se suele primero hacer una primera división entre train y test de 80-20 y luego el de train se utiliza para hacer “cross-validation” al entrenar, la manera más frecuente es k-folds en donde por ejemplo creamos 10 splits y vamos usamos iterativamente 9 particiones como samples de entrenamiento y 1 de validación. Al utilizar este tipo de técnicas disminuimos el riesgo de overfitting. El conjunto de test que separamos inicialmente NUNCA es usado por el modelo al entrenar y se utiliza para obtener un score final (sea este f1, accuracy, AUC, etc.)
Gracias por escribir! Saludos
Interesante este articulo, felicito al autor. Se ha hablado mas del exceso de datos para el modelo PERO que pasa cuando se dispone de “pocos” datos??,…cuando te vez obligado a entrenar al modelo con pocos datos simplemente por no la hay… Por ejmplo digamos que quiero cnstruir un programa en IA que tome como entradas las llamadas de un call center (4 o 5 llamadas al año) y a estas llamadas debo clasificarlas por tematica antes de dar la respectiva respuesta… en este caso QUE TIPO de algoritmo o metodo debería aplicar? gracias de antemano LUCHO
Hola Juan,
Gracias por compartir! En los siguientes párrafos:
“ Si el modelo entrenado con el conjunto de test tiene un 90% de aciertos y con el conjunto de validación tiene un porcentaje muy bajo, esto señala claramente un problema de overfitting.
Si en el conjunto de validación sólo se acierta un tipo de clase (por ejemplo «peras») o el único resultado que se obtiene es siempre el mismo valor será que se produjo un problema de underfitting.”
Te refieres al conjunto de validación al de entrenamiento?
Suelo utilizar de entrenamiento y pruebas pero esto de validación me confunde un poco.
Gracias
Me encanta este blog!! Muchas gracias por este tipo de sitios web !!
Hola María, gracias por participar en el blog!
Saludos
Excelente explicación! Muchas gracias!
Hola Jovany, muchas gracias por participar en el blog.
ME alegro que gustara la explicación!
Saludos
Excelente explicación, muchas gracias.
Gracias 😄
Hola,
Muy bueno el blog, ya estoy suscrito y me leo los nuevos artículos cada vez que me llega un mail.
Me queda una duda sobre la primera explicación…
En el primer ejemplo (donde se explica el overfitting vs underfitting)
para la explicacion de overfitting se podría pensar que “faltaron” perros pelo largo blancos en el entrenamiento?
o sea nuevamente underfitting?
Muy bueno el blog, podrias por favor ayudarme con esta duda…
(Texto citado)
Por el contrario, si entrenamos a nuestra máquina con 10 razas de perros sólo de color marrón de manera rigurosa y luego enseñamos una foto de un perro blanco, nuestro modelo no podrá reconocerlo cómo perro por no cumplir exactamente con las características que aprendió (el color forzosamente debía ser marrón). Aquí se trata de un problema de overfitting.
¿Como puede ser overfitting cuando “faltaron” imágenes de perros blancos en el entrenamiento?
Espero puedas ayudarme a resolver esta duda que no me deja avanzar en la comprensión del concepto.
Saludos
Hola! Muy bueno tu blog, solo que le añadiría referencias de los temas abordados para seguir investigando. Felicidades.
Hola Patricio, muchas gracias por el comentario, intentaré agregar más referencias, saludos