
Breve Introducción a la Regresión Logística
Utilizaremos algoritmos de Machine Learning en Python para resolver un problema de Regresión Logística. A partir de un conjunto de datos de entrada (características), nuestra salida será discreta (y no continua) por eso utilizamos Regresión Logística (y no Regresión Lineal). La Regresión Logística es un Algoritmo Supervisado y se utiliza para clasificación.

Vamos a clasificar problemas con dos posibles estados “SI/NO”: binario o un número finito de “etiquetas” o “clases”: múltiple. Algunos Ejemplos de Regresión Logística son:
- Clasificar si el correo que llega es Spam o No es Spam
- Dados unos resultados clínicos de un tumor clasificar en “Benigno” o “Maligno”.
- El texto de un artículo a analizar es: Entretenimiento, Deportes, Política ó Ciencia
- A partir de historial bancario conceder un crédito o no
Confiaremos en la implementación del paquete sklearn en Python para ponerlo en práctica.
Ejercicio de Regresión Logística en Python
Para nuestro ejercicio he creado un archivo csv con datos de entrada a modo de ejemplo para clasificar si el usuario que visita un sitio web usa como sistema operativo Windows, Macintosh o Linux.
Nuestra información de entrada son 4 características que tomé de una web que utiliza Google Analytics y son:
- Duración de la visita en Segundos
- Cantidad de Páginas Vistas durante la Sesión
- Cantidad de Acciones del usuario (click, scroll, uso de checkbox, sliders,etc)
- Suma del Valor de las acciones (cada acción lleva asociada una valoración de importancia)
Como la salida es discreta, asignaremos los siguientes valores a las etiquetas:
0 – Windows
1 – Macintosh
2 -Linux
La muestra es pequeña: son 170 registros para poder comprender el ejercicio, pero recordemos que para conseguir buenos resultados siempre es mejor contar con un número abundante de datos que darán mayor exactitud a las predicciones y evitarán problemas de overfitting u underfitting. (Por decir algo, de mil a 5 mil registros no estaría mal).
Requerimientos técnicos
Para ejecutar el código necesitas tener instalado Python -tanto la versión 2.7 o 3.6- y varios paquetes usados comúnmente en Data Science. Recomiendo tener instalada la suite Anaconda o Canopy, muy sencillas y con los paquetes para “Data Science” ya pre-instalados y funcionan en todas las plataformas.
Para este ejemplo he creado un block de notas Jupyter donde se muestra paso a paso el ejercicio. Se puede descargar desde aqui o se puede seguir online desde el Jupyter Notebook Viewer.
Regresión Logística con SKLearn:
Identificar Sistema Operativo de los usuarios
Para comenzar hacemos los Import necesarios con los paquetes que utilizaremos en el Ejercicio.
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd import numpy as np from sklearn import linear_model from sklearn import model_selection from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import seaborn as sb %matplotlib inline |
Leemos el archivo csv (por sencillez, se considera que estará en el mismo directorio que el archivo de notebook .ipynb) y lo asignamos mediante Pandas a la variable dataframe. Mediante el método dataframe.head() vemos en pantalla los 5 primeros registros.
|
1 2 |
dataframe = pd.read_csv(r"usuarios_win_mac_lin.csv") dataframe.head() |
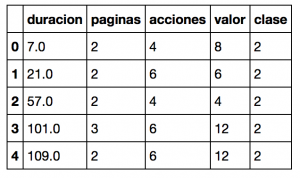
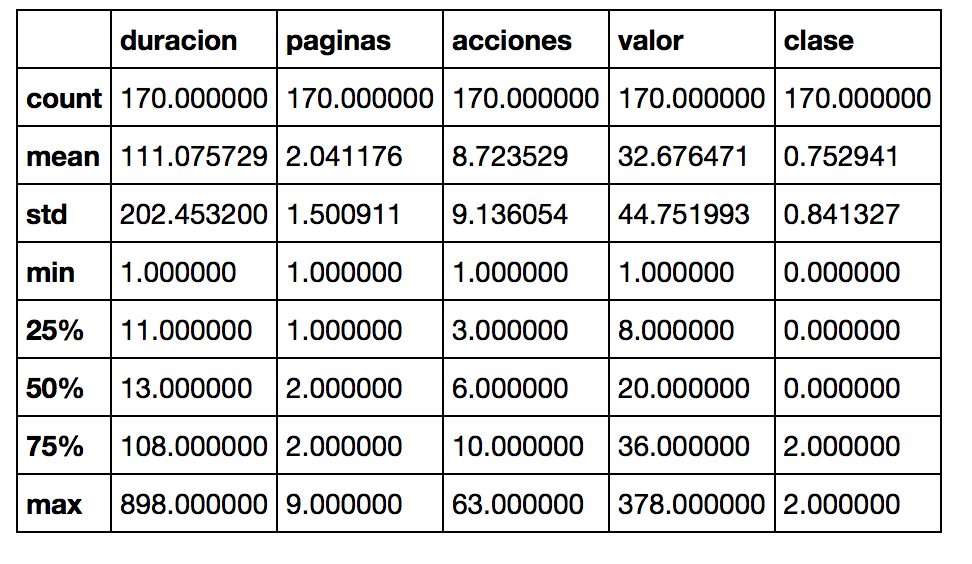
A continuación llamamos al método dataframe.describe() que nos dará algo de información estadística básica de nuestro set de datos. La Media, el desvío estándar, valores mínimo y máximo de cada característica.
|
1 |
dataframe.describe() |
Luego analizaremos cuantos resultados tenemos de cada tipo usando la función groupby y vemos que tenemos 86 usuarios “Clase 0”, es decir Windows, 40 usuarios Mac y 44 de Linux.
|
1 |
print(dataframe.groupby('clase').size()) |

Visualización de Datos
Antes de empezar a procesar el conjunto de datos, vamos a hacer unas visualizaciones que muchas veces nos pueden ayudar a comprender mejor las características de la información con la que trabajamos y su correlación.
Primero visualizamos en formato de historial los cuatro Features de entrada con nombres “duración”, “páginas”,”acciones” y “valor” podemos ver gráficamente entre qué valores se comprenden sus mínimos y máximos y en qué intervalos concentran la mayor densidad de registros.
|
1 2 |
dataframe.drop(['clase'],1).hist() plt.show() |
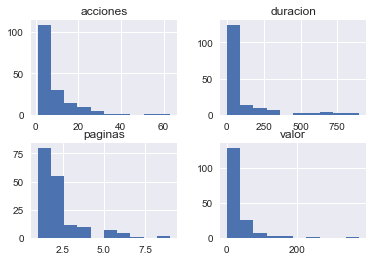
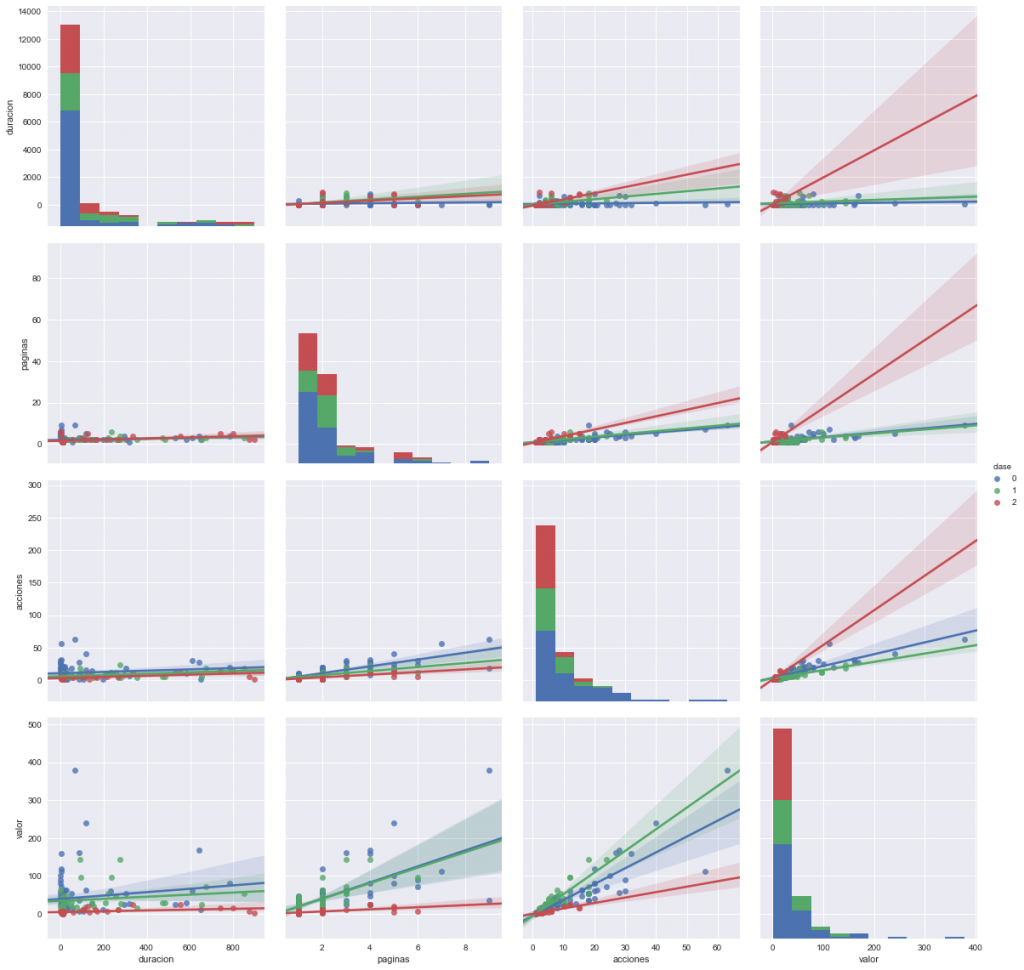
Y también podemos interrelacionar las entradas de a pares, para ver como se concentran linealmente las salidas de usuarios por colores: Sistema Operativo Windows en azul, Macintosh en verde y Linux en rojo.
|
1 |
sb.pairplot(dataframe.dropna(), hue='clase',size=4,vars=["duracion", "paginas","acciones","valor"],kind='reg') |
Creamos el Modelo de Regresión Logística
Ahora cargamos las variables de las 4 columnas de entrada en X excluyendo la columna “clase” con el método drop(). En cambio agregamos la columna “clase” en la variable y. Ejecutamos X.shape para comprobar la dimensión de nuestra matriz con datos de entrada de 170 registros por 4 columnas.
|
1 2 3 |
X = np.array(dataframe.drop(['clase'],1)) y = np.array(dataframe['clase']) X.shape |
(170, 4)
Y creamos nuestro modelo y hacemos que se ajuste (fit) a nuestro conjunto de entradas X y salidas ‘y’.
|
1 2 |
model = linear_model.LogisticRegression() model.fit(X,y) |
<
p class=””>LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class=’ovr’, n_jobs=1,
penalty=’l2′, random_state=None, solver=’liblinear’, tol=0.0001,
verbose=0, warm_start=False)
Una vez compilado nuestro modelo, le hacemos clasificar todo nuestro conjunto de entradas X utilizando el método “predict(X)” y revisamos algunas de sus salidas y vemos que coincide con las salidas reales de nuestro archivo csv.
|
1 2 |
predictions = model.predict(X) print(predictions)[0:5] |
[2 2 2 2 2]
Y confirmamos cuan bueno fue nuestro modelo utilizando model.score() que nos devuelve la precisión media de las predicciones, en nuestro caso del 77%.
|
1 |
model.score(X,y) |
0.77647058823529413
Validación de nuestro modelo
Una buena práctica en Machine Learning es la de subdividir nuestro conjunto de datos de entrada en un set de entrenamiento y otro para validar el modelo (que no se utiliza durante el entrenamiento y por lo tanto la máquina desconoce). Esto evitará problemas en los que nuestro algoritmo pueda fallar por “sobregeneralizar” el conocimiento.
Para ello, subdividimos nuestros datos de entrada en forma aleatoria (mezclados) utilizando 80% de registros para entrenamiento y 20% para validar.
|
1 2 3 |
validation_size = 0.20 seed = 7 X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, y, test_size=validation_size, random_state=seed) |
Volvemos a compilar nuestro modelo de Regresión Logística pero esta vez sólo con 80% de los datos de entrada y calculamos el nuevo scoring que ahora nos da 74%.
|
1 2 3 4 5 |
name='Logistic Regression' kfold = model_selection.KFold(n_splits=10, random_state=seed) cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy') msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std()) print(msg) |
Logistic Regression: 0.743407 (0.115752)
Y ahora hacemos las predicciones -en realidad clasificación- utilizando nuestro “cross validation set”, es decir del subconjunto que habíamos apartado. En este caso vemos que los aciertos fueron del 85% pero hay que tener en cuenta que el tamaño de datos era pequeño.
|
1 2 |
predictions = model.predict(X_validation) print(accuracy_score(Y_validation, predictions)) |
0.852941176471
Finalmente vemos en pantalla la “matriz de confusión” donde muestra cuantos resultados equivocados tuvo de cada clase (los que no están en la diagonal), por ejemplo predijo 3 usuarios que eran Mac como usuarios de Windows y predijo a 2 usuarios Linux que realmente eran de Windows.
Reporte de Resultados del Modelo
|
1 |
print(confusion_matrix(Y_validation, predictions)) |

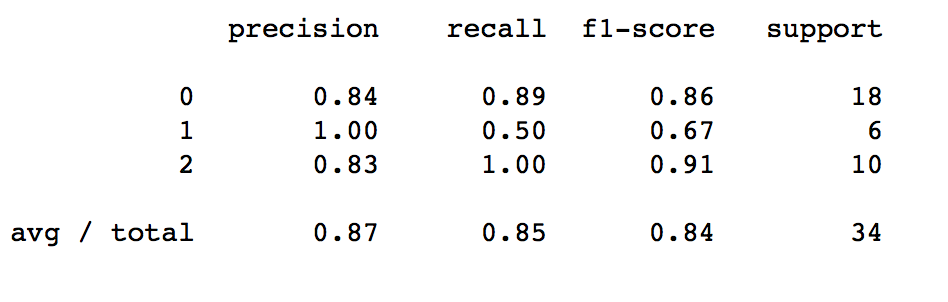
También podemos ver el reporte de clasificación con nuestro conjunto de Validación. En nuestro caso vemos que se utilizaron como “soporte” 18 registros windows, 6 de mac y 10 de Linux (total de 34 registros). Podemos ver la precisión con que se acertaron cada una de las clases y vemos que por ejemplo de Macintosh tuvo 3 aciertos y 3 fallos (0.5 recall). La valoración que de aqui nos conviene tener en cuenta es la de F1-score, que tiene en cuenta la precisión y recall. El promedio de F1 es de 84% lo cual no está nada mal.
|
1 |
print(classification_report(Y_validation, predictions)) |
Clasificación (o predicción) de nuevos valores
Como último ejercicio, vamos a inventar los datos de entrada de navegación de un usuario ficticio que tiene estos valores:
- Tiempo Duración: 10
- Paginas visitadas: 3
- Acciones al navegar: 5
- Valoración: 9
Lo probamos en nuestro modelo y vemos que lo clasifica como un usuario tipo 2, es decir, de Linux.
|
1 2 |
X_new = pd.DataFrame({'duracion': [10], 'paginas': [3], 'acciones': [5], 'valor': [9]}) model.predict(X_new) |
array([2])
Los invito a jugar y variar estos valores para obtener usuarios de tipo Windows o Macintosh.
En este ejercicio las 3 clases están equilibradas, pero ¿Qué pasa si tengo desbalanceo de datos? Aqui te lo cuento!
Conclusiones
Durante este artículo vimos cómo crear un modelo de Regresión Logística en Python para poder clasificar el Sistema Operativo de usuarios a partir de sus características de navegación en un sitio web. A partir de este ejemplo, se podrá extender a otro tipos de tareas que pueden surgir durante nuestro trabajo en el que deberemos clasificar resultados en valores discretos. Si tuviéramos que predecir valores continuos, deberemos aplicar Regresión Lineal.
Espero que puedan seguir correctamente el ejercicio y si tienen inconvenientes técnicos me escriben en los comentarios para solucionarlos o si encuentran mejoras al texto/ejercicio, también espero sus sugerencias. Recuerda descargar los archivos para realizar el Ejercicio:
- Archivo de Entrada csv (su nombre es usuarios_win_mac_lin.csv)
- Notebook Jupyter Python (clic derecho y “descargar archivo como…”)
- OPCIÓN 2: Se puede ver online en Jupyter Notebook Viewer
- OPCIÓN 3: Se puede visualizar y descargar el Notebook y el csv desde mi cuenta de Github
Si te interesa aprender algoritmos con Python, ahora está disponible “K-means” paso a paso y árbol de decisión te invito a leerlos.
Como siempre los invito a suscribirse al blog y a compartir las entradas en Redes Sociales para que podamos aumentar nuestra comunidad de “estudiantes” aprendiendo Machine Learning!
Suscripción Aprende Machine Learning
Suscribe al blog y te llegará el aviso del próximo artículo semanal/quincenal sobre Machine Learning.
Hasta la próxima!
Hola, quisiera saber que algoritmo de machine learning me serviría para clasificar a mis clientes. Creo que Kmeans es el algoritmo utilizado en estos casos. Lo que me gustaría conseguir es optimizar la publicidad para conocer los perfiles más comunes de mis clientes y segmentarlos.
Muchas gracias
Hola Borja, si tienes características de tus clientes y no los tienes etiquetados, es una muy buena opción aplicar k-means para crear (y descubrir) clusters (grupos) de perfiles (pues es un algoritmo sin supervisión). Una vez que obtengas el valor óptimo de K (es decir, la cantidad de grupos) y ejecutado el algoritmo, deberás analizar el resultado para ver cual es el centro de cada grupo y comprender lo que los hace únicos y diferenciales del resto de grupos. Si necesitas ayuda me avisas!. ¿Has visto mi artículo sobre k-means? el enlace es k-means con Python paso a paso. Saludos y espero que nos mantengamos en contacto.
Hola Juan Ignacio…. Lo felicito porque está muy bien explicado este tema…. siga así…. !!!!
Hola efraín, muchas gracias por tus palabras!. Espero poder escribir un nuevo artículo sobre Redes Neuronales con Python pronto!. Saludos y seguimos en contacto
Hola Juan Ignacio…. Estuve replicando este ejemplo tuyo con otra base de datos que tiene entradas mixtas (categóricas y numéricas) con salida categorica (1,2,3) y todo bien hasta cuando se va a crean el model.fit(X,y)
No se si me puedas ayudar a entender porque pasa eso enviando el notebook y la BD. Gracias mil
Efrain, sígueme por Twitter y te paso por mensaje directo mi email para que me adjuntes los archivos. O si quieres, escríbeme por aquí el error que te da y lo revisamos.
Juan Ignacio, de verdad muchas gracias por ayudarnos a todos los que estamos aprendiendo.
Gracias Etienne! Siempre da alegría saber que les puedo ayudar! Espero seguir escribiendo nuevos artículos! Saludos
Hola Juan Ignacio, muchas gracias, y muchas felicidades también por tan loable labor de compartir este conocimiento tan útil, me esta siendo de muchísima ayuda. Tengo una pregunta, en tu dataset en la variable objetivo “clase”, no están niveladas las categorías (86,40,44), al parecer en este caso no afecta en gran medida al resultado porque son pocos datos, pero si tuviéramos el mismo escenario pero con más datos ej. (8725,1230,2300), ¿nos serviría también este algoritmo, o tendríamos que prescindir de algunos datos para nivelar el numero?
Gracias
Hola Iven, gracias por participar en el Blog!. Muy buena tu observación. Te cuento que lo ideal siempre es tener las etiquetas o clases balanceadas. Esto es tener casi la misma cantidad de clases en el conjunto de entrenamiento. Esto es para que el algoritmo supervisado que aprende generalice correctamente el conocimiento. Si no, corremos el riesgo de que tenga un sesgo, o que caiga en Overfitting obteniendo inferencias erróneas.
Hay que tener en cuenta 2 cosas:
* Por una parte, según el algoritmo que utilicemos, tendrá mayor o menor “tolerancia” a estas “clases desniveladas”. Por ejemplo Naive Bayes se comporta bastante bien a pesar de tener pocas muestras de una clase. Sin embargo para Regresión continua o lineal conviene un buen equilibrio.
* Por otra parte, tenemos técnicas para equilibrar las clases “artificialmente”, por ejemplo inventando muestras inexistentes como se suele hacer para redes neuronales que reconocen imágenes: se toma una misma imagen y se la “copia y pega” pero rotada unos grados a la izquierda, o se le aplica algún filtro de desenfoque.
Saludos y espero que te ayude la respuesta!
Muchas gracias por contestar tan rápido Juan Ignacio, me quedó muy clara la respuesta. Ahora bien, me gustaría aprender sobre ese tipo de técnicas que comentas para equilibrar las clases. ¿Tendrás a la mano información de este tipo o algún sitio en donde me pueda informar?
Saludos y nuevamente felicitaciones por este proyecto.
Hola Iven, creo que un buen artículo en inglés es 8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset.
Como verás, hay diversas tácticas a seguir. Puede servirte de punta pié inicial para que busques en Google “imbalanced data” ó “Synthetic Samples”.
El tema es realmente interesante, por lo que lo tendré en cuenta para un futuro artículo!
Muchas gracias Juan Ignacio, seguiré con este tema.
Hola Nacho. Muy buen artículo. Bastante bien explicado, aunque he tenido que buscar ayuda externa de k-fold cross validation, ya que no sabía lo que era (por si la vale a alguien, aquí lo explican muy bien en inglés: https://magoosh.com/data-science/k-fold-cross-validation/). Tengo una preguntilla: si al principio entrenamos el modelo con todos los datos, ¿cómo es que al predecir sobre esos mismos datos obtenemos sólo un 77% de acierto en vez de un 100%? Muchas gracias y un saludo
Hola Alberto, gracias por participar. Con respecto a las definiciones y/o referencias a otros temas como k-folds o cross validación, me acabas de dar una buena idea, que es la de crear un glosario en el blog, en donde podré poner ese tipo de notas. Gracias también por el enlace sobre k-fold.
Con respecto a tu pregunta te respondo: por más que utilizamos todos los datos de nuestro conjunto, el algoritmo será capaz de generalizar el conocimiento hasta un cierto punto. En este caso, logra acertar en el 77% de los casos. Si hubiera dado el 100% seguramente querría decir que está cayendo en Overfiting (lo que es un problema).
En resumen y para que quede claro:
* que utilicemos el 100% de datos no quiere decir que vayamos a tener un 100% de aciertos.
* de hecho, es una mala práctica usar el 100%, pues conviene separar un subconjunto para utilizarlo como test del algoritmo
* Si agregáramos muchas más EPOCHS (iteraciones) al algoritmo puede ser que mejoremos el porcentaje de aciertos, pero seguramente estemos teniendo Overfiting lo cual no es bueno.
Saludos, espero que sigamos en contacto!
¡Muchas gracias por la respuesta! Seguiré leyéndote.
Hola Nacho.
Al ejecutar este código:
predictions = model.predict(X)
print(predictions)[0:5]
me sale este error:
TypeError Traceback (most recent call last)
in ()
1 predictions = model.predict(X)
—-> 2 print(predictions)[0:5]
TypeError: ‘NoneType’ object is not subscriptable
¿podrías ayudarme cómo corregirlo?
Pedro, creo que es un simple error:
Pasar de
print(predictions)[0:5]a
print(predictions[0:5])para felicitarte por tu blog, te comento estoy haciendo una predicción con imágenes usando inteligencia artificial, si me puede colaborar con una guía por que camino me debo ir , ya que es un tema sobre procesamiento de imagen de cáncer
agradezco tu atención.
Hola buenas noches, para consultar cual es el mejor algoritmo que me permite analizar imágenes con inteligencia artificial, agradecería tu colaboración guiándome con el tema, te comento es sobre el análisis de imagen de cáncer para clasificar su porcentaje de efectividad
Hola Edinson, gracias por escribirme y participar del blog. Te comento que “afortunadamente” hay varios experimentos, ejemplos y ejercicios para análisis de imágenes de cáncer para clasificar e identificar casos benignos o malignos.
Como algoritmo, si tu entrada son imágenes yo utilizaría Convolutional Neural Network (CNN). Si cuentas con otras features, por ej información específica del tumor y ubicación, datos de los pacientes, podrías intentar mezclar tb un algoritmo como Naive Bayes ó Regresión Logística.
Te dejo aquí una lista de artículos que he encontrado y que te pueden servir:
Creo me está faltando alguna otra cosilla para recomendarte, pero ahora mismo por falta de tiempo no puedo. Más adelante intentaré agregar más información.
Saludos!
Muchas gracias bro, me sirvio mucho tu explicacion y la verdad muy entendible.
Me alegra que sirva! Y gracias Josh por visitar el blog! Saludos
Hola Juan Ignacio! Excelente ejercicio, bien explicado.
Recomiendo para realizar practicas Colab de Google, puedes utlizar numpy, Pandas,Sickit Learn…
Una pregunta, crees que puedo utlizar un modelo de regresion logistica e un problema donde tengo
* La ubicacion.
* La fecha.
* Franja horaria
* Si fue o no fue un accidente
Para predecir en donde y cuando va a ocurrir un accidente automovilistico. Te agradecieria tu opinion y consejos. Gracias!
Hola subjonctifblog, Justo acabo de publicar un nuevo artículo sobre Gooble Colab y cómo utilizarlo! gracias por el consejo 😉
Te cuento que para el tipo de problema que planteas puedes usar Regresión, SVM ó lo mejor serían Redes Neuronales Recursivas, de hecho mejor las de tipo LSTM y realizar predicciones de tipo “forecast” es decir dependientes de tiempo (time series). Tengo pensado escribir al respecto próximamente. Saludos y si necesitas enlaces, dime y te paso unos cuantos! Saludos
Hola de nuevo Juan Ignacio, gracias por tu consejo, espero poder probar con al menos dos algoritmos de los que me sugieres.
Algo muy importante que se me olvido preguntar en la otra ocasion es que tengo un dataset desbalanceado, mi variable respuesta es algo asi:
0 788070
1 36517
Name: Accident, dtype: int64
0 – No hubo accidente en ese lugar
1 – Si hubo accidente en ese lugar
La pregunta entoces seria como puedo balancear el dataset porque ahora el modelo es genial prediciendo no’s pero de lo contrario es malisimo, te agradeceria mucho tu ayuda. Gracias!
Hola, mira, para dataset desbalanceados tienes diversas alternativas:
1-intentar conseguir más muestras de la clase que tienes menos
2-Usar un algoritmo que no le afecte mucho el desbalanceo como Naive Bayes (ó Arbol decisión con “class_weight”)
3-Recortar el dataset, en tu caso, usar por ej: las 36.000 casos de tipo 1 y tomar sólo 72.000 del tipo 0 en vez de todos para entrenar. PERO ojo con esto, pues podrías estar introduciendo un sesgo. Deberás tener en cuenta como “mezclar” las de tipo 0 para que sean representativas.
4-Si tuvieras la posibilidad de hacer “data augmentation”.
5-Cambiar el foto de tu problema: por ej. en vez de hacer predicción, hacer detección de anomalías.
Por el momento esas se me ocurren!.
Saludos
Gracias por compartir sus conocimientos, me ha ayudado mucho.
Hola Misael, muchas gracias por escribir! seguimos en contacto! Saludos
Hola Juan Ignacio, muchas gracias por todas tus publicaciones, son super faciles de comprender.
Te quería preguntar que me aconsejas para hacer una regresion logistica para determinar la probabilidad de 9 clases, teniendo en cuenta que tengo variables categoricas y numericas, mi variable a predecir es categórica, intente convertir toda la variable en dummie, pero el algoritmo que indicas no me funciona. Tal vez sera porque son demasiadas clases?
O como defino mi variable a predecir y las predictorias?
gracias Juan Ignacio
Saludos,
Hola Diana, me puedes escribir al formulario y así me comentas mejor por email, pues no comprendo del todo tu pregunta. Si puedes dime concretamente qué variables tienes, de qué es el problema que intentas resolver, para ver si entiendo mejor.
Saludos y gracias por escribir!
hola, muy buena la practica. Mi pregunta es la siguiente: por qué el modelo predice 3 tipos de resultados 0, 1 y 2 y no otros? es decir segun entiendo divide el conjunto de datos en 3 tipos, bajo que parametros determina esto? y por otro lado que diga 0, 1 y 2 bajo que parametro determinamos que valor corresponde a cada S.O.? GRACIAS!
Hola iñaki, en este caso, ya vienen definidos los tipo de sistema operativo como 0,1 y 2 en el archivo csv de entrada. Si hubiéramos definido otros números serían esos. O si hubieran sido cadenas de texto o por ejemplo “a,b,c” habría que convertirlos a valores categóricos. Saludos y gracias por escribir!
estimado,
hay algo que me cuesta comprender, al ingresar un conjunto de datos y solicitar que nos determine a que clase pertenece, por que nos da solo 3 resultados? bajo qué parametros determina los distintos resultados?
Hola Juan Ignacio, que sentencia utilizarías en el ejemplo para hacer un K-S test, y el p-value test? Gracias
Hola Juan Ignacio,
Cuando dices “Y ahora hacemos las predicciones -en realidad clasificación- utilizando nuestro «cross validation set», es decir del subconjunto que habíamos apartado. En este caso vemos que los aciertos fueron del 85% pero hay que tener en cuenta que el tamaño de datos era pequeño..”, no veo que escribas:
model.fit(X_train, Y_train)
¿No sería necesario antes de calcular las predicciones y su scoring? De esa manera el modelo no habría aprendido previamente de todo el data set cuando lo hemos hecho .fit() pero con todos los datos.
Gracias
Tienes razon men, no lo habia notado se debe de ajustar a los vaores de entrenamiento
prueba con un RANDOM_STATE=99 para que obtengas el valor mas alto del accuracy.
buenas, te felicito por la pagina. Consulta, el dataset solo tiene que tener variables cuantitativas o dummies?
hola men, gracias por compartir tu conocimiento, una consulta sabes por que el valor que tome el RANDOM_STATE influye mucho en el valor del score?
Por ejemplo usaste un valor de random_state=7 y con ese lograste superar el score que se uso sin dividir la data en train/test, pero si le ponemos otros valores al random_state el valor del score cambia, sabes como influye mucho el valor del random_state? como elegir el mejor valor del random_state? se que si no lo usas te cambia la data por lo que es mecesario darle un valor pero como saber cual es el mejor valor?
He visto que podemos tomar un rango y graficar los scores, para ver en cual es el mas alto: algo asi
scores=[]
for i in range(1,100):
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.20,random_state=i)
kfold = KFold(n_splits=10, random_state=42)
cv_results = model_selection.cross_val_score(modelo, X_train, y_train, cv=kfold,
scoring=’accuracy’)
predicciones2 = modelo.predict(X_test)
scores.append([i,accuracy_score(y_test, predicciones2)])
for i in range(1,100):
plt.plot(scores[i-1][0],scores[i-1][1],marker=’x’)
el cambio se da por el RANDOM_STATE en el train_split, en el kfold no influye el valor del random:state
Hola Juan, que algoritmo recomiendas para predecir el crecimiento de las plantas utilizando valores como cantidad de luz, temperatura, etc? He intentado con regresión lineal pero el error cuadrático es muy alto