
K-Nearest-Neighbor es un algoritmo basado en instancia de tipo supervisado de Machine Learning. Puede usarse para clasificar nuevas muestras (valores discretos) o para predecir (regresión, valores continuos). Al ser un método sencillo, es ideal para introducirse en el mundo del Aprendizaje Automático. Sirve esencialmente para clasificar valores buscando los puntos de datos “más similares” (por cercanía) aprendidos en la etapa de entrenamiento (ver 7 pasos para crear tu ML) y haciendo conjeturas de nuevos puntos basado en esa clasificación.

A diferencia de K-means, que es un algoritmo no supervisado y donde la “K” significa la cantidad de “grupos” (clusters) que deseamos clasificar, en K-Nearest Neighbor la “K” significa la cantidad de “puntos vecinos” que tenemos en cuenta en las cercanías para clasificar los “n” grupos -que ya se conocen de antemano, pues es un algoritmo supervisado-.
¿Qué es el algoritmo k-Nearest Neighbor ?
Es un método que simplemente busca en las observaciones más cercanas a la que se está tratando de predecir y clasifica el punto de interés basado en la mayoría de datos que le rodean. Como dijimos antes, es un algoritmo:
- Supervisado: esto -brevemente- quiere decir que tenemos etiquetado nuestro conjunto de datos de entrenamiento, con la clase o resultado esperado dada “una fila” de datos.
- Basado en Instancia: Esto quiere decir que nuestro algoritmo no aprende explícitamente un modelo (como por ejemplo en Regresión Logística o árboles de decisión). En cambio memoriza las instancias de entrenamiento que son usadas como “base de conocimiento” para la fase de predicción.
¿Dónde se aplica k-Nearest Neighbor?
Aunque sencillo, se utiliza en la resolución de multitud de problemas, como en sistemas de recomendación, búsqueda semántica y detección de anomalías.
Pros y contras
Como pros tiene sobre todo que es sencillo de aprender e implementar. Tiene como contras que utiliza todo el dataset para entrenar “cada punto” y por eso requiere de uso de mucha memoria y recursos de procesamiento (CPU). Por estas razones kNN tiende a funcionar mejor en datasets pequeños y sin una cantidad enorme de features (las columnas).
Para reducir la cantidad de dimensiones (features) podemos aplicar PCA
¿Cómo funciona kNN?
- Calcular la distancia entre el item a clasificar y el resto de items del dataset de entrenamiento.
- Seleccionar los “k” elementos más cercanos (con menor distancia, según la función que se use)
- Realizar una “votación de mayoría” entre los k puntos: los de una clase/etiqueta que <<dominen>> decidirán su clasificación final.
Teniendo en cuenta el punto 3, veremos que para decidir la clase de un punto es muy importante el valor de k, pues este terminará casi por definir a qué grupo pertenecerán los puntos, sobre todo en las “fronteras” entre grupos. Por ejemplo -y a priori- yo elegiría valores impares de k para desempatar (si las features que utilizamos son pares). No será lo mismo tomar para decidir 3 valores que 13. Esto no quiere decir que necesariamente tomar más puntos implique mejorar la precisión. Lo que es seguro es que cuantos más “puntos k”, más tardará nuestro algoritmo en procesar y darnos respuesta 
Las formas más populares de “medir la cercanía” entre puntos son la distancia Euclidiana (la “de siempre”) o la Cosine Similarity (mide el ángulo de los vectores, cuanto menores, serán similares). Recordemos que este algoritmo -y prácticamente todos en ML- funcionan mejor con varias características de las que tomemos datos (las columnas de nuestro dataset). Lo que entendemos como “distancia” en la vida real, quedará abstracto a muchas dimensiones que no podemos “visualizar” fácilmente (como por ejemplo en un mapa).
Hagamos un ejemplo k-Nearest Neighbor en Python
Exploremos el algoritmo con Scikit learn
Realizaremos un ejercicio usando Python y su librería scikit-learn que ya tiene implementado el algoritmo para simplificar las cosas. Veamos cómo se hace.
Requerimientos
Para realizar este ejercicio, crearemos una Jupyter notebook con código Python y la librería SkLearn muy utilizada en Data Science. Recomendamos utilizar la suite para python de Anaconda. Puedes leer este artículo donde muestro paso a paso como instalar el ambiente de desarrollo. Podrás descargar los archivos de entrada csv o visualizar la notebook online (al final de este artículo los enlaces).
El Ejercicio y el Código: App Reviews
Para nuestro ejercicio tomaremos 257 registros con Opiniones de usuarios sobre una app (Reviews). Utilizaremos 2 columnas de datos como fuente de alimento del algoritmo. Recuerden que sólo tomaré 2 features para poder graficar en 2 dimensiones, PERO para un problema “en la vida real” conviene tomar más características de lo que sea que queramos resolver. Esto es únicamente con fines de enseñanza. Las columnas que utilizaremos serán: wordcount con la cantidad de palabras utilizadas y sentimentValue con un valor entre -4 y 4 que indica si el comentario fue valorado como positivo o negativo. Nuestras etiquetas, serán las estrellas que dieron los usuarios a la app, que son valores discretos del 1 al 5. Podemos pensar que si el usuario puntúa con más estrellas, tendrá un sentimiento positivo, pero no necesariamente siempre es así.
Comencemos con el código!
Primero hacemos imports de librerías que utilizaremos para manejo de datos, gráficas y nuestro algoritmo.
Cargamos el archivo entrada csv con pandas, usando separador de punto y coma, pues en las reviews hay textos que usan coma. Con head(10) vemos los 10 primeros registros.
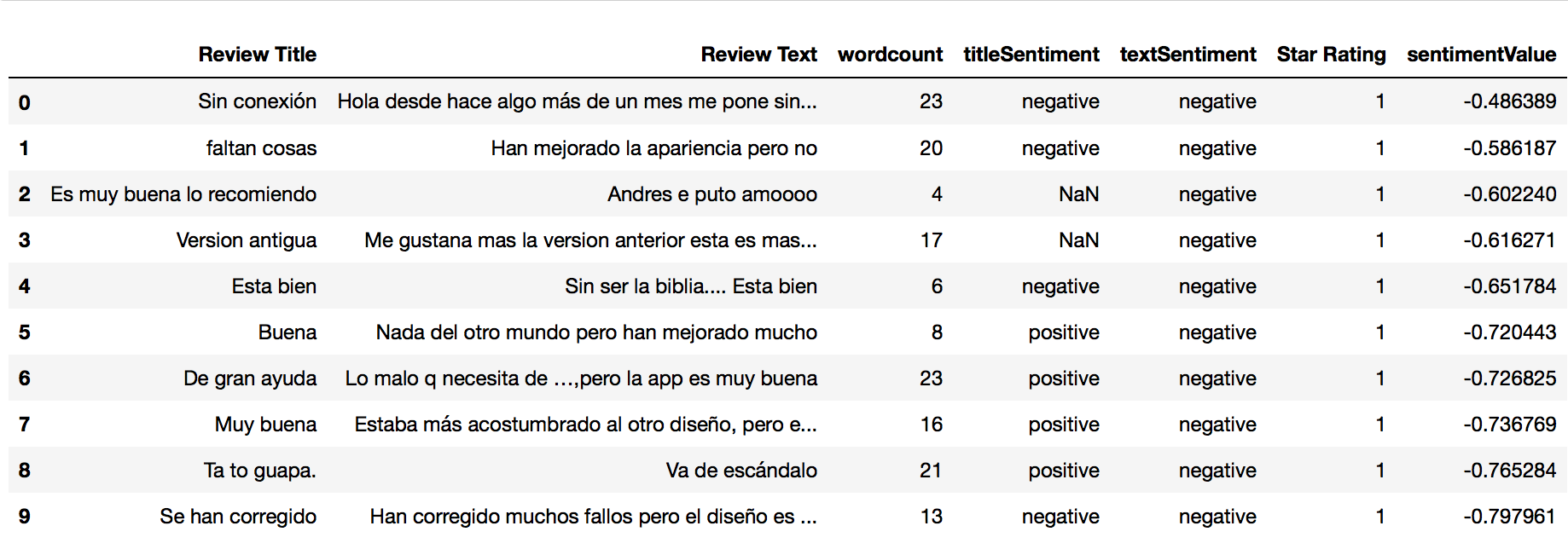
Aprovechamos a ver un resumen estadístico de los datos:
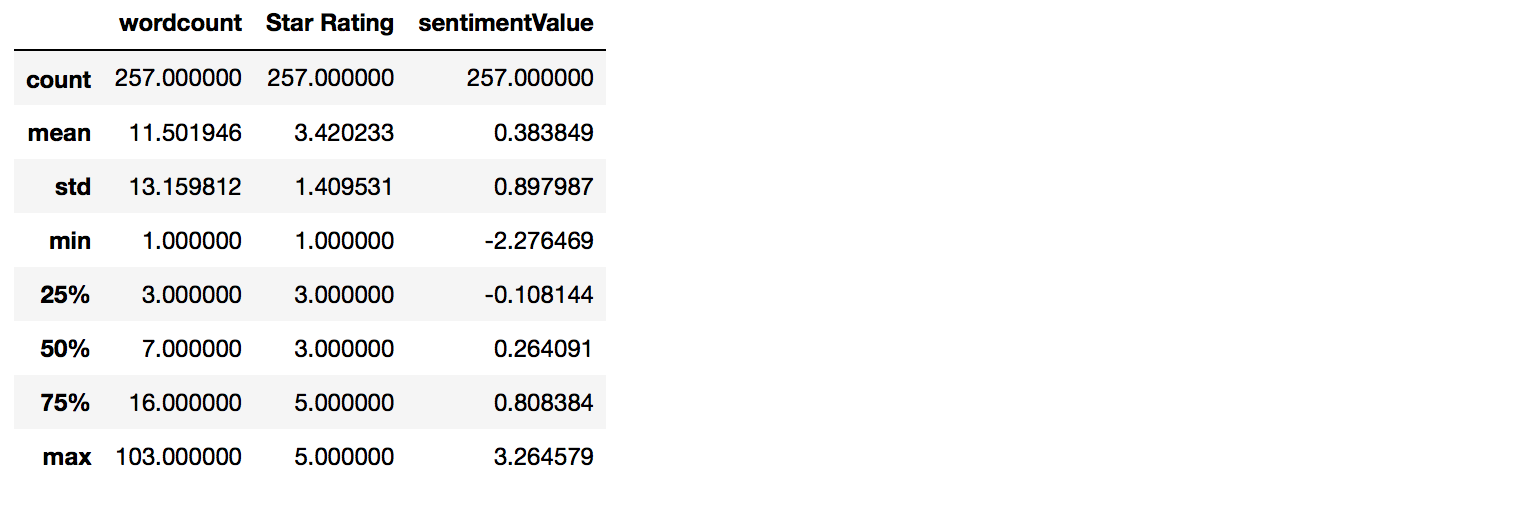
Son 257 registros. Las estrellas lógicamente vemos que van del 1 al 5. La cantidad de palabras van de 1 sóla hasta 103. y las valoraciones de sentimiento están entre -2.27 y 3.26 con una media de 0,38 y a partir del desvío estándar podemos ver que la mayoría están entre 0,38-0,89 y 0,38+0,89.
Un poco de Visualización
Veamos unas gráficas simples y qué información nos aportan:
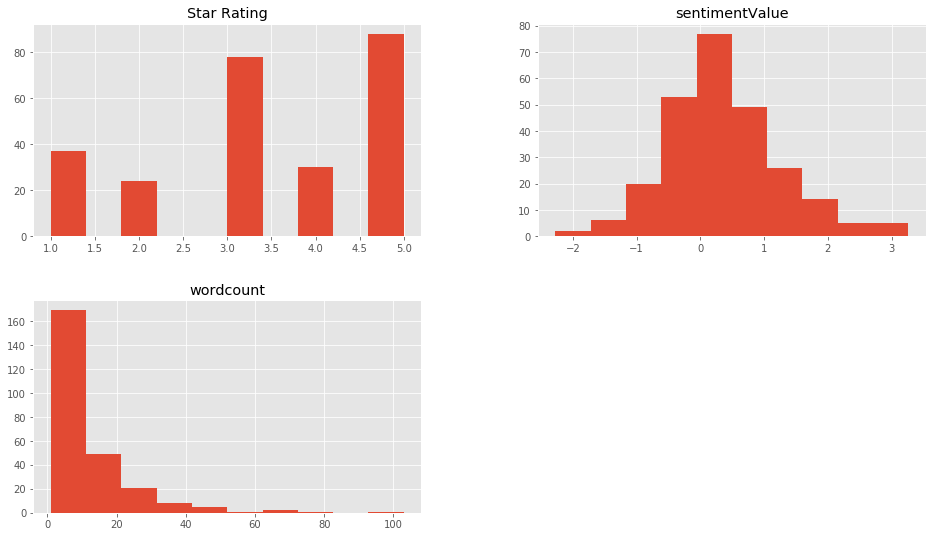
Vemos que la distribución de “estrellas” no está balanceada… esto no es bueno. Convendría tener las mismas cantidades en las salidas, para no tener resultados “tendenciosos”. Para este ejercicio lo dejaremos así, pero en la vida real, debemos equilibrarlos. La gráfica de Valores de Sentimientos parece bastante una campana movida levemente hacia la derecha del cero y la cantidad de palabras se centra sobre todo de 0 a 10.
Veamos realmente cuantas Valoraciones de Estrellas tenemos:

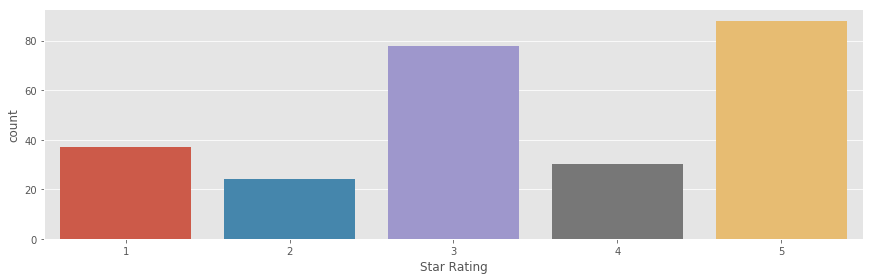
Con eso confirmamos que hay sobre todo de 3 y 5 estrellas.
Y aqui una gráfica más bonita:
Graficamos mejor la cantidad de palabras y confirmamos que la mayoría están entre 1 y 10 palabras.
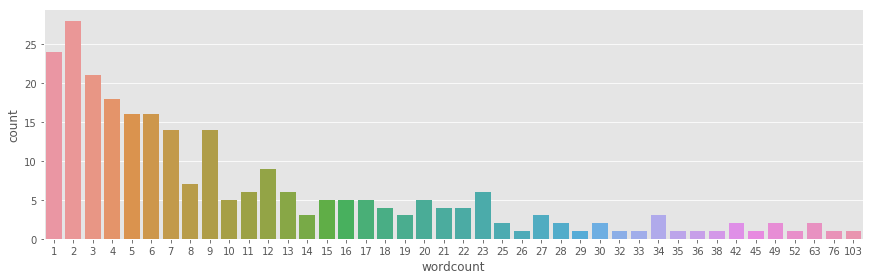
Preparamos las entradas
Creamos nuestro X e y de entrada y los sets de entrenamiento y test.
Usemos k-Nearest Neighbor con Scikit Learn
Definimos el valor de k en 7 (esto realmente lo sabemos más adelante, ya veréis) y creamos nuestro clasificador.
Accuracy of K-NN classifier on training set: 0.90
Accuracy of K-NN classifier on test set: 0.86
Vemos que la precisión que nos da es de 90% en el set de entrenamiento y del 86% para el de test.
NOTA: como verán utilizamos la clase KNeighborsClassifier de SciKit Learn puesto que nuestras etiquetas son valores discretos (estrellas del 1 al 5). Pero deben saber que también existe la clase KneighborsRegressor para etiquetas con valores continuos.
Precisión del modelo
Confirmemos la precisión viendo la Confusión Matrix y el Reporte sobre el conjunto de test, que nos detalla los aciertos y fallos:
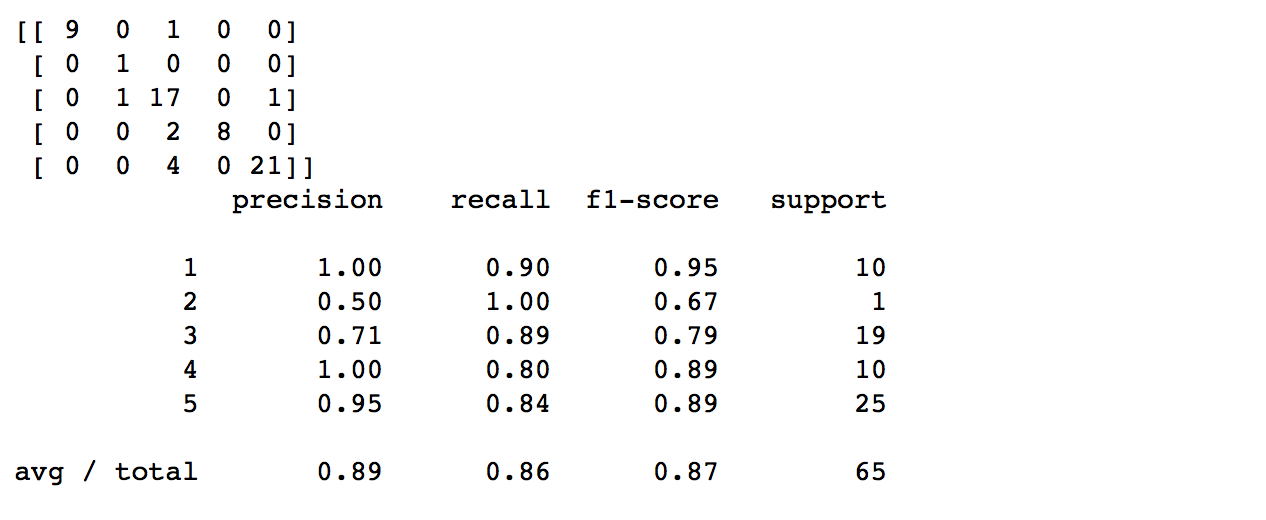
Cómo se ve la puntuación F1 es del 87%, bastante buena. NOTA: recuerden que este es sólo un ejercicio para aprender y tenemos MUY pocos registros totales y en nuestro conjunto de test. Por ejemplo de 2 estrellas sólo tiene 1 valoración y esto es evidentemente insuficiente.
Y ahora, la gráfica que queríamos ver!
Ahora realizaremos la grafica con la clasificación obtenida, la que nos ayuda a ver fácilmente en donde caerán las predicciones. NOTA: al ser 2 features, podemos hacer la gráfica 2D y si fueran 3 podría ser en 3D. Pero para usos reales, podríamos tener más de 3 dimensiones y no importaría poder visualizarlo sino el resultado del algoritmo.
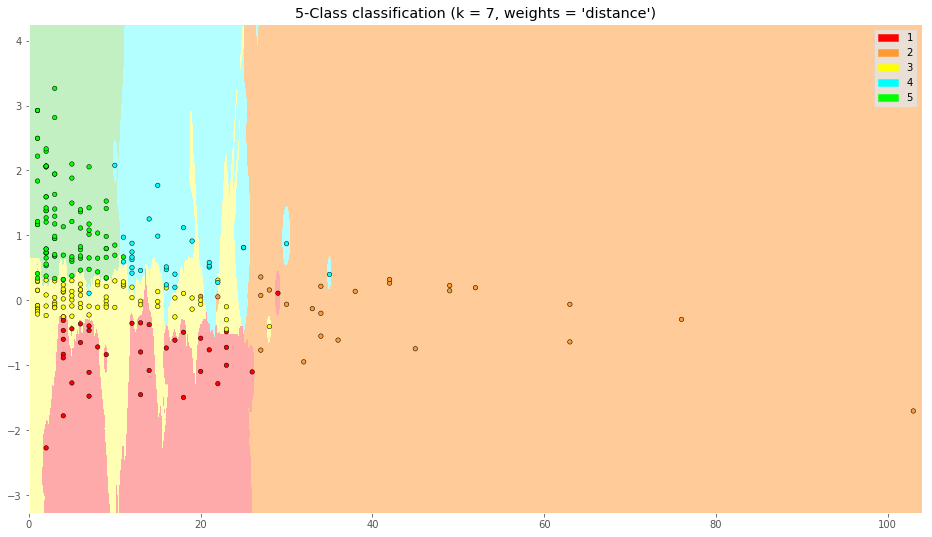
Vemos las 5 zonas en las que se relacionan cantidad de palabras con el valor de sentimiento de la Review que deja el usuario.
Se distinguen 5 regiones que podríamos dividir así:
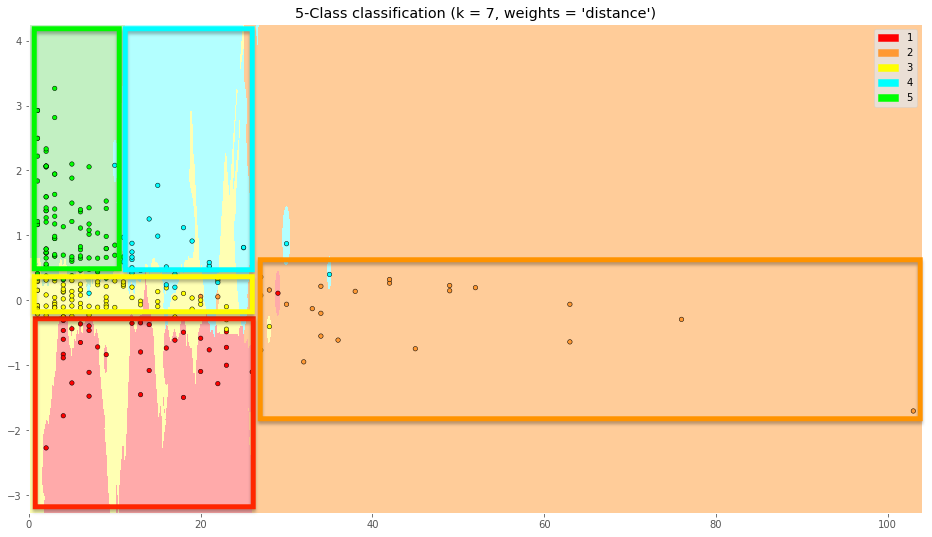
Es decir que “a ojo” una review de 20 palabras y Sentimiento 1, nos daría una valoración de 4 (zona celeste).
Con estas zonas podemos intuir ciertas características de los usuarios que usan y valoran la app:
- Los usuarios que ponen 1 estrella tienen sentimiento negativo y hasta 25 palabras.
- Los usuarios que ponen 2 estrellas dan muchas explicaciones (hasta 100 palabras) y su sentimiento puede variar entre negativo y algo positivo.
- Los usuarios que ponen 3 estrellas son bastante neutrales en sentimientos, puesto que están en torno al cero y hasta unas 25 palabras.
- Los usuarios que dan 5 estrellas son bastante positivos (de 0,5 en adelante, aproximadamente) y ponen pocas palabras (hasta 10).
Elegir el mejor valor de k
(sobre todo importante para desempatar o elegir los puntos frontera!)
Antes vimos que asignamos el valor n_neighbors=7 como valor de “k” y obtuvimos buenos resultados. ¿Pero de donde salió ese valor?. Pues realmente tuve que ejecutar este código que viene a continuación, donde vemos distintos valores k y la precisión obtenida.
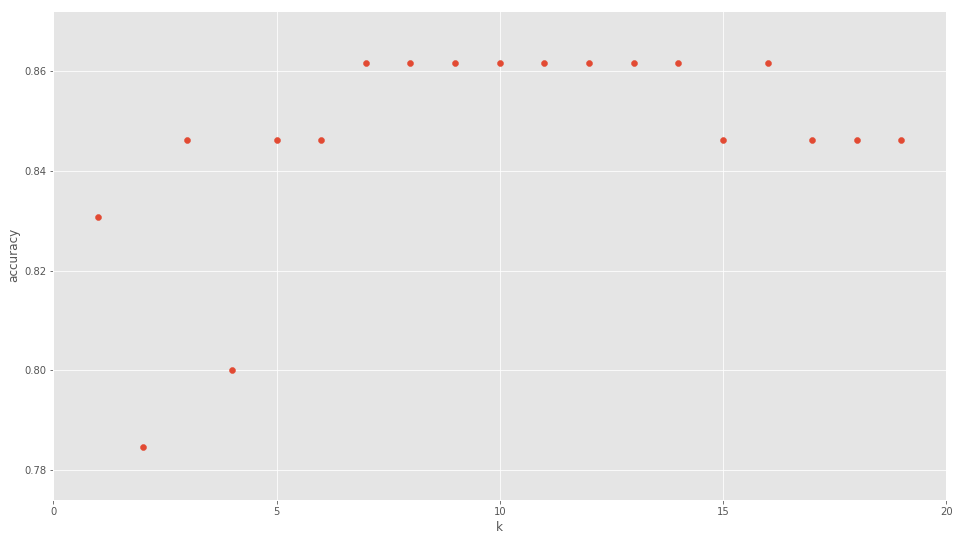
En la gráfica vemos que con valores k=7 a k=14 es donde mayor precisión se logra.
Clasificar y/o Predecir nuevas muestras
Ya tenemos nuestro modelo y nuestro valor de k. Ahora, lo lógico será usarlo! Pues supongamos que nos llegan nuevas reviews! veamos como predecir sus estrellas de 2 maneras. La primera:
[5]
Este resultado nos indica que para 5 palabras y sentimiento 1, nos valorarán la app con 5 estrellas.
Pero también podríamos obtener las probabilidades que de nos den 1, 2,3,4 o 5 estrellas con predict_proba():
[[0.00381998 0.02520212 0.97097789 0. 0. ]]
Aquí vemos que para las coordenadas 20, 0.0 hay 97% probabilidades que nos den 3 estrellas. Puedes comprobar en el gráfico anterior, que encajan en las zonas que delimitamos anteriormente.
Conclusiones del algoritmo kNN
En este ejercicio creamos un modelo con Python para procesar y clasificar puntos de un conjunto de entrada con el algoritmo k-Nearest Neighbor. Cómo su nombre en inglés lo dice, se evaluán los “k vecinos más cercanos” para poder clasificar nuevos puntos. Al ser un algoritmo supervisado debemos contar con suficientes muestras etiquetadas para poder entrenar el modelo con buenos resultados. Este algoritmo es bastante simple y -como vimos antes- necesitamos muchos recursos de memoria y cpu para mantener el dataset “vivo” y evaluar nuevos puntos. Esto no lo hace recomendable para conjuntos de datos muy grandes. En el ejemplo, sólo utilizamos 2 dimensiones de entrada para poder graficar y ver en dos dimensiones cómo se obtienen y delimitan los grupos. Finalmente pudimos hacer nuevas predicciones y a raíz de los resultados, comprender mejor la problemática planteada.
Suscripción al Blog
Recibe el próximo artículo quincenal sobre Machine Learning y buenas prácticas Python
Puedes hacer más ejercicios Machine Learning en Python en nuestra categoría d Ejercicios paso a paso por ejemplo de Regresión Logística ó clustering K-means ó comprender y crear una Sencilla Red Neuronal.
Recursos y enlaces del ejercicio
- Descarga la Jupyter Notebook y el archivo de entrada csv
- ó puedes visualizar online
- o ver y descargar desde mi cuenta github
Más artículos de Interés sobre k-Nearest Neighbor (en Inglés)
- Implementing kNN in scikit learn
- Introduction to kNN
- Complete guide to kNN
- Solving a simple classification problem with Python
Otras Herramientas:
- Hacer WebScraping con Python y obtener contenidos de cualquier página web.
El libro del Blog
Puedes ayudar a este autor comprando el libro ó lo puedes descargar gratuitamente. Aún está en borrador, pero apreciaré mucho tu ayuda! Contiene Extras descargables como el “Lego Dataset” utilizado en el artículo de Detección de Objetos.



Gracias, Juan Ignacio, por esta entrada. Me ha resultado muy ilustrativa.
Tan sólo indicar que he tenido dos dificultades con el código: al leer el fichero csv (hay que indicar “encoding=’latin-1′”) y determinados valores de “sentiment” dentro de este mismo fichero tienen un formato que da problemas al crear los sets de entrenamiento y prueba (los he asimilado a otros valores válidos). No sé si es el caso de otros usuarios, pero lo indico por si sirve de ayuda.
Tengo una pregunta relativa a cómo se puede indicar que la distancia sea euclídea, gaussiana o de Mahalanobis al aplicar k-NN y por qué deberíamos emplear una u otra.
Gracias.
Andrés.
Hola Andrés, muchas gracias por escribir y por tu aporte para resolver esos problemas de encoding, yo uso mac e imagino que tendrá que ver con el cambio de sistema operativo.
Para podel cambiar a distintas funciones de distancia, de dejo el enlace a la documentación Documentación kNN Métricas de donde comenta poder usar: [‘cityblock’, ‘cosine’, ‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’] y otras 17 más. Si a pesar de eso, quieres crear una función propia “custom”, también puedes (con lambda), como lo muestran en este enlace: create custom distance function . Otro enlace.
Saludos!
Hola Nacho. gran artículo, como siempre. Tengo una pregunta: he probado a ejecutar el modelo sin escalar los valores de X (o sea, sin usar MinMaxScaler) y el accuracy ha bajado a 0.78 en training y 0.74 en test. ¿Esto por qué sucede? ¿KNN necesita tener los valores de X entre 0 y 1? ¡Muchas gracias!
Funciona igualmente, pero funciona “mejor” con entradas escaladas de 0 a 1 (normalizadas). Te dejo un enlace: Practical Guide on Data Preprocessing in Python
Muchas gracias, Nacho. Parece un artículo muy interesante. Le echaré un vistazo en cuanto tenga tiempo.
Si no escalas los valores, implícitamente KNN entiende que los valores con mayor magnitud son más importantes que los que tenga un rango menor. Esto sucede porque para calcular los vecinos, KNN utiliza distancias (ya sea Euclidea, Manhattan, etc.).
Para obtener mejores resultados con KNN te ofrezco dos recomendaciones:
1. escalar las entradas
2. intentar que todos los atributos sean relevantes.
Por ejemplo, si además del número de palabras de la opinión escrita y su sentimiento, incluimos la altura (en centímetros) de la persona que escribió la opinión … seguramente los resultados de KNN serían peores.
Esto es normal porque la técnica de los vecinos más cercanos es una técnica de machine learning no-supervisada. Al no poder establecer la relación entre los datos de entrada y los resultados, la responsabilidad de identificar los atributos relevantes recae sobre nosotros.
Saludos y gracias por este artículo! Tengo una duda, cuando corro el programa “clf” me dice que no existe. Será que estoy haciendolo mal? Gracias.
Hola Brian, gracias por escribir. Eso tiene pinta que no está el import de sklearn del Clasificador. Te recomiendo que descargues/mires el código completo en https://github.com/jbagnato/machine-learning/blob/master/Ejercicio_k-NearestNeighbor.ipynb Saludos
Hola Brian, te cuento que no esta disponible el archivo
pero ya encontre el error. Como no copie el codigo del grafico porque tengo multiples variables, entonces no estaba definida la funcion. Seleccione del graficos las lineas a1 a 7 y asi logre impriir uego el resultado
Hola Juan Ignacio, estoy tratando de seguir el ejercicio, sin embargo me sale el siguiente error:
MemoryError Traceback (most recent call last)
in ()
13 x_min, x_max = X[:, 0].min() – 1, X[:, 0].max() + 1
14 y_min, y_max = X[:, 1].min() – 1, X[:, 1].max() + 1
—> 15 xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
16 np.arange(y_min, y_max, h))
17 Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
MemoryError:
Hola Karen, tu comentario justo se corta donde iba la descripción del error.
Te molestaría enviármelo COMPLETO desde el formulario de contacto? Y así puedo examinarlo bien.
Saludos y gracias
donde puedo obtener el dataset
Al final del artículo está el enlace, te lo comparto aquí de nuevo
saludos
Gracias Juan Ignacio por este articulo de gran ayuda para lo que iniciamos ,queria consultarte sobre lo que decis”que la distribución de «estrellas» no está balanceada… esto no es bueno. Convendría tener las mismas cantidades en las salidas, para no tener resultados «tendenciosos»” hay algun metodo o forma de lograrlo.Muchas gracias
Hola. Alguien sabe si estoy puede funcionar a gran escala para categorizar muchos datos ?
Hola, muy buen artículo. La duda que tengo es como predecir los valores en instancias posteriores, si no me arroja los coeficientes? Lo pregunto porque en instancias posteriores ya no me queda guardada la función «clf.predict()»
Hola, gracias por escribir.
Luego de entrenar con fit al modelo que en este caso está en la variable llamada “clf” puedes guardarlo en un archivo en formato pickle de python y cuando lo necesitas en el futuro lo lees de ese archivo y puedes seguir haciendo predict sobre nuevos inputs.
Saludos!
Gracias, Juan Ignacio por tan buen trabajo, yo quiero saber el consumo de ram del algoritmo, ya que para la parte y fragmento de código ” Y ahora, la gráfica que queríamos ver!”, siempre consume la totalidad de mi ram 8G, hago pruebas sobre Google Colab y pasa igual con 12G. Gracias y atento a tus comentarios.
Hola Nestor, gracias por escribir!
Te cuento que este algoritmo trabaja en memoria y mientras “vive” utilizará toda la ram que necesita. Si tienes un dataset muy bestial ocupará mucha memoria. Para el ejemplo de mi notebook del artículo no consume mucha RAM porque son pocos registros, si con la gráfica te consume mucho debe ser un error de programación por ejemplo que quede un bucle ejecutando continuamente ó que tengas una versión con bugs de la librería gráfica. SI no, es imposible que llegue a 8GB! ni mucho menos!
Saludos, cualquier cosa me dices!
Muchas gracias estimado, me sirvió bastante.
Juan buenas tardes muy bueno el articulo. Te queria consultar acerca de la ultima parte donde generas los graficos de mapa de calor, lo que no me queda claro es por que volves a Clasificar directamente con X e y los puntos con esta parte del codigo :
we create an instance of Neighbours Classifier and fit the data.
clf = KNeighborsClassifier(n_neighbors, weights=’distance’)
clf.fit(X, y)
El modelo que se genera con
knn = KNeighborsClassifier(n_neighbors)
knn.fit(X_train, y_train)
No se usa mas? no es con este con el que se predice? ahi es donde me perdi, o en clf utiliza el mismo fit generado para luego predecir?
tengo la misma duda que Juan Pedro…
Hola Catalina, Si te fijas, cuando entrenamos por primera vez, usa un subconjunto llamado X_Train, en cambio luego para usarlo por completo, tomamos todas las muestras, en la variable X. Por eso hace el fit nuevamente y recrea el modelo.
Saludos!
Buenos días. Me sale el siguiente error: Donde defino ‘LABELS’?
NameError Traceback (most recent call last)
C:\Users\FABIAN~1\AppData\Local\Temp/ipykernel_17232/1681503347.py in
1 count_classes = pd.value_counts(df[‘Falla’], sort = True)
2 count_classes.plot(kind = ‘bar’, rot=0)
—-> 3 plt.xticks(range(2), LABELS)
4 plt.title(«numero de muestras por falla»)
5 plt.xlabel(«Falla»)
NameError: name ‘LABELS’ is not defined
Hola Ignacio, estoy haciendo el mismo ejercicio pero con otro conjunto de prueba, mi consulta esta en la visualización es decir no me queda claro como determinas que es 7 el mejor valor…