
Hoy veremos un nuevo ejercicio práctico, intentando llevar los algoritmos de Machine Learning a ejemplos claros y de la vida real, repasaremos la teoría del Teorema de Bayes (video) de estadística para poder tomar una decisión muy importante: ¿me conviene comprar casa ó alquilar?

Veamos si la Ciencia de Datos nos puede ayudar a resolver el misterio… ¿Si alquilo estoy tirando el dinero a la basura? ó ¿Es realmente conveniente pagar una hipoteca durante el <<resto de mi vida>>?
Si bien tocaremos el tema livianamente -sin meternos en detalles como intereses de hipotecas variable/fija, porcentajes, comisiones de bancos,etc- haremos un planteo genérico para obtener resultados y tomar la mejor decisión dada nuestra condición actual.
En artículos pasados vimos diversos algoritmos Supervisados del Aprendizaje Automático que nos dejan clasificar datos y/o obtener predicciones o asistencia a la toma de decisiones (árbol de decisión, regresión logística y lineal, red neuronal). Por lo general esos algoritmos intentan minimizar algún tipo de coste iterando las entradas y las salidas y ajustando internamente las “pendientes” ó “pesos” para hallar una salida. Esta vez, el algoritmo que usaremos se basa completamente en teoría de probabilidades y obteniendo resultados estadísticos. ¿Será suficiente el Teorema de Bayes para obtener buenas decisiones? Veamos!
¿Qué necesitaras para programar?
Para realizar este ejercicio, crearemos una Jupyter notebook con código Python y la librería SkLearn muy utilizada en Data Science. Recomendamos utilizar la suite para Python de Anaconda. Puedes leer este artículo donde muestro paso a paso como instalar el ambiente de desarrollo. Podrás descargar los archivos de entrada csv o visualizar la notebook online (al final de este artículo los enlaces).
Nuestros Datos de Entrada:
Importemos las librerías que usaremos y visualicemos la información que tenemos de entrada:
Y carguemos la info del archivo csv:
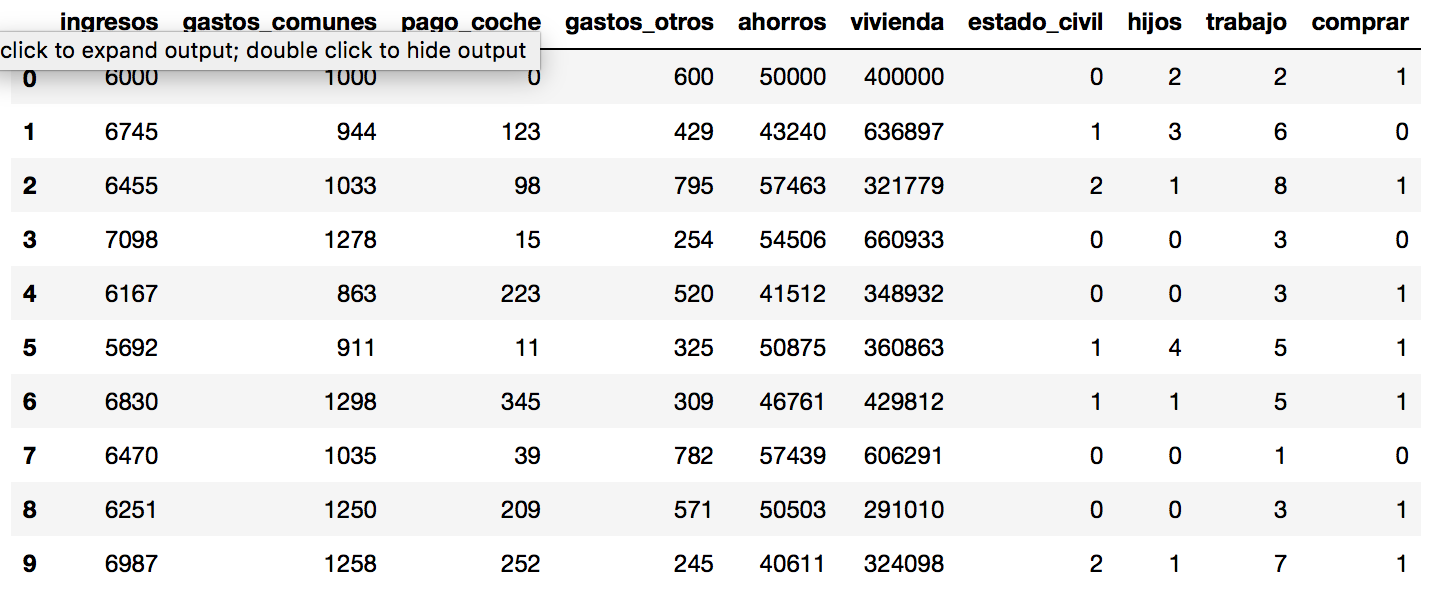 Las columnas que tenemos son:
Las columnas que tenemos son:
- ingresos: los ingresos de la familia mensual
- gastos comunes: pagos de luz, agua, gas, etc mensual
- pago coche: si se está pagando cuota por uno o más coches, y los gastos en combustible, etc al mes.
- gastos_otros: compra en supermercado y lo necesario para vivir al mes
- ahorros: suma de ahorros dispuestos a usar para la compra de la casa.
- vivienda: precio de la vivienda que quiere comprar esa familia
- estado civil:
- 0-soltero
- 1-casados
- 2-divorciados
- hijos: cantidad de hijos menores y que no trabajan.
- trabajo:
- 0-sin empleo 1-autónomo (freelance)
- 2-empleado
- 3-empresario
- 4-pareja: autónomos
- 5-pareja: empleados
- 6-pareja: autónomo y asalariado
- 7-pareja:empresario y autónomo
- 8-pareja: empresarios los dos o empresario y empleado
- comprar: 0-No comprar 1-Comprar (esta será nuestra columna de salida, para aprender)
Algunos supuestos para el problema formulado:
- Está pensado en Euros pero podría ser cualquier otra moneda
- No tiene en cuenta ubicación geográfica, cuando sabemos que dependerá mucho los precios de los inmuebles de distintas zonas
- Se supone una hipoteca fija a 30 años con interés de mercado “bajo”.
Con esta información, queremos que el algoritmo aprenda y que como resultado podamos consultar nueva información y nos dé una decisión sobre comprar (1) o alquilar (0) casa.
El teorema de Bayes
- El teorema de Bayes es una ecuación que describe la relación de probabilidades condicionales de cantidades estadísticas. En clasificación bayesiana estamos interesados en encontrar la probabilidad de que ocurra una “clase” dadas unas características observadas (datos). Lo podemos escribir como P( Clase | Datos). El teorema de Bayes nos dice cómo lo podemos expresar en términos de cantidades que podemos calcular directamente:
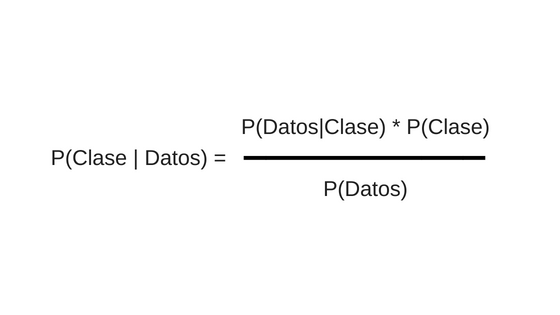
- Clase es una salida en particular, por ejemplo “comprar”
- Datos son nuestras características, en nuestro caso los ingresos, gastos, hijos, etc
- P(Clase|Datos) se llama posterior (y es el resultado que queremos hallar)
- P(Datos|Clase) se llama “verosimilitud” (en inglés likelihood)
- P(Clase) se llama anterior (pues es una probabilidad que ya tenemos)
- P(Datos) se llama probabilidad marginal
Si estamos tratando de elegir entre dos clases como en nuestro caso “comprar” ó “alquilar”, entonces una manera de tomar la decisión es calcular la tasa de probabilidades a posterior:
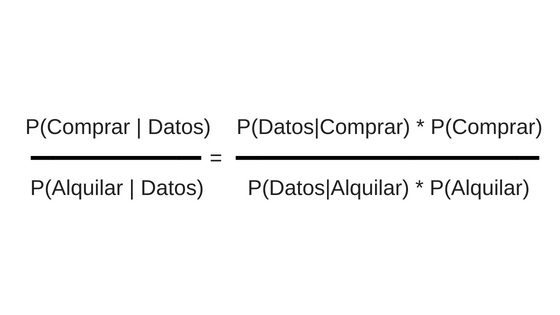
con esta maniobra, nos deshacemos del denominador de la ecuación anterior P(Datos) el llamado “probabilidad marginal”.
Clasificador Gaussian Naive Bayes
Uno de los tipos de clasificadores más populares es el llamado en inglés Gaussian Naive Bayes Classifier. NOTA:Hay otros clasificadores Bayesianos que no veremos en este artículo. Veamos cómo es su fórmula para comprender este curioso nombre: aplicaremos 2 clases (comprar, alquilar) y tres características: ingresos, ahorros e hijos.
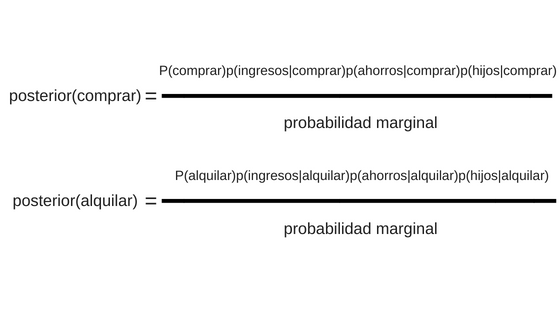
Posterior de comprar es lo que queremos hallar: P(comprar|datos).
Explicaremos los demá:
- P(comprar) es la probabilidad que ya tenemos. Es sencillamente el número de veces que se selecciona comprar =1 en nuestro conjunto de datos, dividido el total de observaciones. En nuestro caso (luego lo veremos en Python) son 67/202
- p(ingresos|comprar)p(ahorros|comprar)p(hijos|comprar) es la verosimilitud. Los nombres Gaussian y Naive (ingenuo) del algoritmo vienen de dos suposiciones:
- asumimos que las características de la verosimilitud no estan correlacionada entre ellas. Esto seria que los ingresos sean independientes a la cantidad de hijos y de los ahorros. Como no es siempre cierto y es una suposición ingenua es que aparece en el nombre “naive bayes”
- Asumimos que el valor de las características (ingresos, hijos, etc) tendrá una distribución normal (gaussiana). Esto nos permite calcular cada parte p(ingresos|comprar) usando la función de probabilidad de densidad normal.
- probabilidad marginal muchas veces es difícil de calcular, sin embargo, por la ecuación que vimos más arriba, no la necesitaremos para obtener nuestro valor a posterior. Esto simplifica los cálculos.
Bien!, Fin de teoría, sigamos con el ejercicio! Ahora toca visualizar nuestras entradas y programar un poquito.
Visualización de Datos
Veamos qué cantidad de muestras de comprar o alquilar tenemos:
comprar
0 135
1 67
dtype: int64
Esto son 67 que entradas en las que se recomienda comprar y 135 en las que no.
Hagamos un histograma de las características quitando la columna de resultados (comprar):
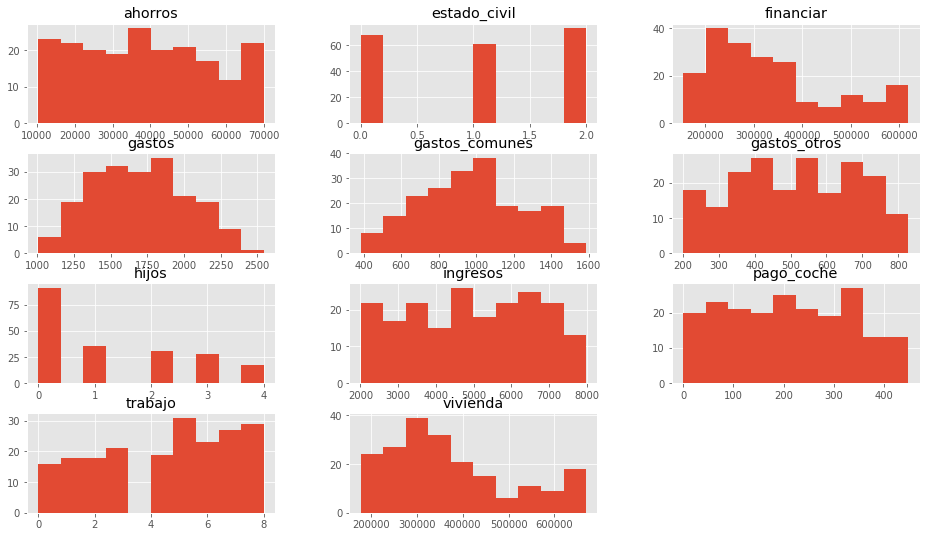
Pareciera a grandes rasgos que la distribución de hijos e ingresos <<se parece>> un poco a una distribución normal.
Preparar los datos de entrada
Vamos a hacer algo: procesemos algunas de estas columnas. Por ejemplo, podríamos agrupar los diversos gastos. También crearemos una columna llamada financiar que será la resta del precio de la vivienda con los ahorros de la familia.
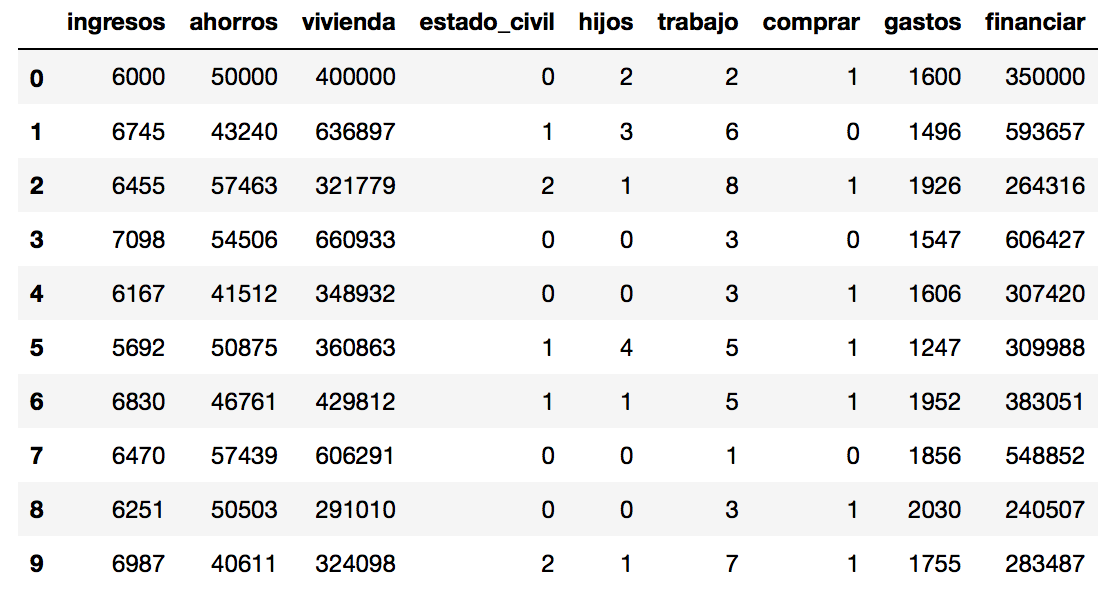
Y ahora veamos un resumen estadístico que nos brinda la librería Pandas con describe():
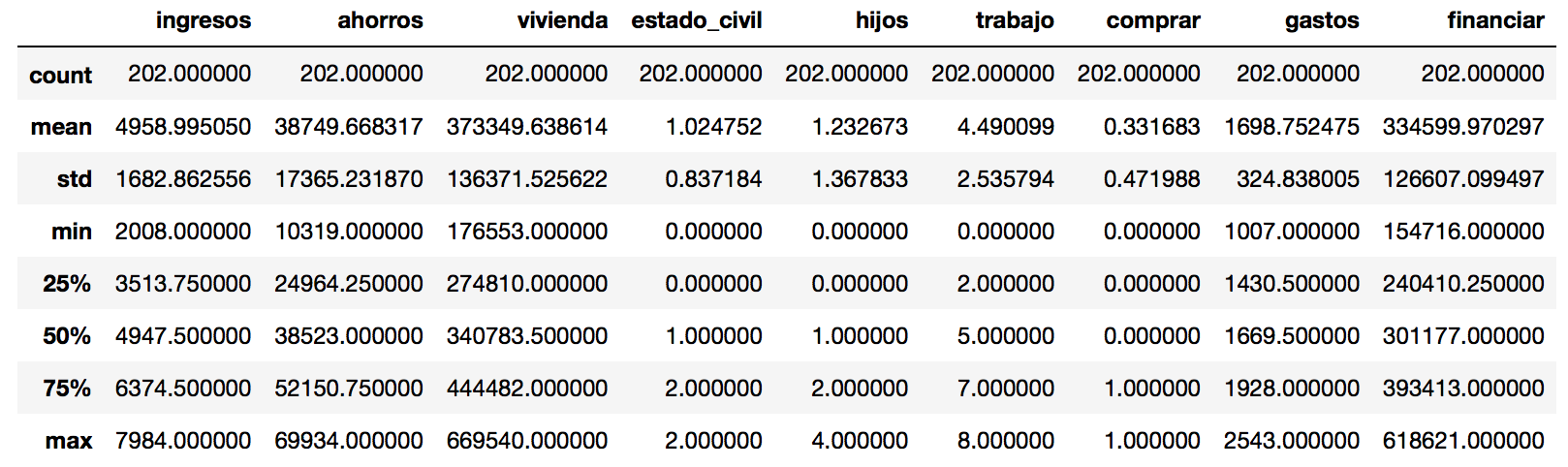
Feature Selection ó Selección de Características
En este ejercicio haremos Feature Selection para mejorar nuestros resultados con este algoritmo. En vez de utilizar las 11 columnas de datos de entrada que tenemos, vamos a utilizar una Clase de SkLearn llamada SelectKBest con la que seleccionaremos las 5 mejores características y usaremos sólo esas.
Index([‘ingresos’, ‘ahorros’, ‘hijos’, ‘trabajo’, ‘financiar’], dtype=’object’)
Bien, entonces usaremos 5 de las 11 características que teníamos. Las que “más aportan” al momento de clasificar. Veamos qué grado de correlación tienen:
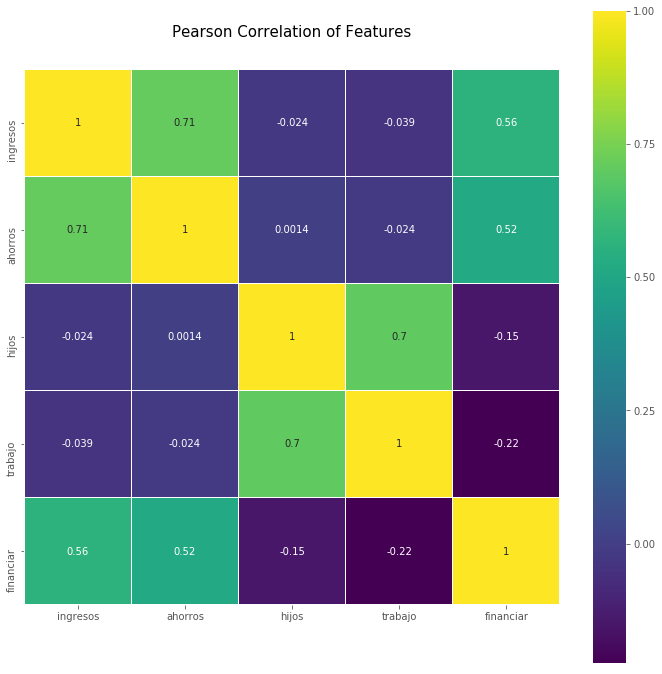
Con esto comprobamos que en general están poco correlacionadas, sin embargo también tenemos 2 valores de 0,7. Esperemos que el algoritmo sea lo suficientemente “naive” para dar buenos resultados 
Otra alternativa para Feture Selection es utilizar Principal Component Analysis (PCA) y hacer reducción de Dimensión
Crear el modelo Gaussian Naive Bayes con SKLearn
Primero vamos a dividir nuestros datos de entrada en entrenamiento y test.
Y creamos el modelo, lo ponemos a aprender con fit() y obtenemos predicciones sobre nuestro conjunto de test.
Precisión en el set de Entrenamiento: 0.87
Precisión en el set de Test: 0.90
Pues hemos obtenido un bonito 90% de aciertos en el conjunto de Test con nuestro querido clasificador bayesiano. También puedes ver los resultados obtenidos aplicando PCA en este otro artículo!
Probemos el modelo: ¿Comprar o Alquilar?
Ahora, hagamos 2 predicciones para probar nuestra máquina:
- En un caso será una familia sin hijos con 2.000€ de ingresos que quiere comprar una casa de 200.000€ y tiene sólo 5.000€ ahorrados.
- El otro será una familia con 2 hijos con ingresos por 6.000€ al mes, 34.000 en ahorros y consultan si comprar una casa de 320.000€.
[0 1]
Los resultados son los esperados, en el primer caso, recomienda Alquilar (0) y en el segundo comprar la casa (1).
Conclusiones
A lo largo del artículo repasamos el teorema de Bayes y vimos un ejemplo para aplicarlo en una toma de decisiones. Pero no olvidemos que en el proceso también hicimos pre procesamiento de los datos, visualizaciones y Selección de Características. Durante diversas charlas que tuve con profesionales del Data Science en mi camino de aprendizaje sale un mismo mensaje que dice: “No es tan importante el algoritmo a aplicar si no la obtención y pre procesamiento de los datos que se van a utilizar”. A tenerlo en cuenta!
Naive Bayes como clasificador se utiliza mucho en NLP (Natural Language Processing) tanto en el típico ejemplo de detectar “Spam” o no como en tareas más complejas como reconocer un idioma o detectar la categoría apropiada de un artículo de texto. También puede usarse para detección de intrusiones o anomalías en redes informáticas y para diagnósticos médicos dados unos síntomas observados. Por último veamos los pros y contras de utilizar Gaussian Naive Bayes:
- Pros: Es rápido, simple de implementar, funciona bien con conjunto de datos pequeños, va bien con muchas dimensiones (features) y llega a dar buenos resultados aún siendo “ingenuo” sin que se cumplan todas las condiciones de distribución necesarias en los datos.
- Contras: Requiere quitar las dimensiones con correlación y para buenos resultados las entradas deberían cumplir las 2 suposiciones de distribución normal e independencia entre sí (muy difícil que sea así ó deberíamos hacer transformaciones en lo datos de entrada).
Si les gustó el artículo les pido como favor si pueden ayudarme a difundir estas páginas en vuestras redes sociales.
Además, como siempre, los invito a suscribirse al Blog ingresando una dirección de email y recibirán una notificación cada 15 días (aprox.) con un nuevo artículo sobre Aprende Machine Learning!.
Suscripción al Blog
Recibe el próximo artículo quincenal sobre Data Science y Machine Learning con Python
Más Recursos y descarga el Código
- El código lo puedes ver en mi cuenta de Github ó …
- lo puedes descargar desde aquí Jupyter Notebook Ejercicio Bayes Python Code
- Descarga el archivo csv de entrada comprar_alquilar.csv
Otros artículos de interés sobre Bayes y Python en Inglés:
Muchas gracias amigo
Hola Riki, espero que el artículo haya sido de tu interés!, saludos
Muy interesante el tema!
Hola Michaell, gracias por comentar! espero que sigas visitando más artículos del blog. Saludos
Muy bueno el artículo!, muchas gracias. Una consulta: como hago para usar un archivo CVS para hacer las predicciones y que la predicción quede guardada en el mismo archivo como un campo más?
Hola Mariano, gracias por escribir!. Para guardar el archivo es tan sencillo como agregar la columna en el dataframe de Pandas que tengas creado y luego hacer df.to_csv(“nombre_archivo.csv”).
Hola Juan Ignacio, estoy realizando mi primer proyecto de Machine Learning y me estoy guiando por tu ejemplo y explicación, muchas gracias por compartir todo el conocimiento que brindas en el blog, saludos.
Hola Michael Andrés, muchas gracias por participar en el Blog y espero que avances con tus proyectos!, seguimos en contacto. Saludos
Hola Juan Ignacio:
Esta es la segunda o tercera vez que visito tu página, y la verdad que me parece fantástico la manera que explicas las cosas, Felicitaciones!!!
Me he suscrito y espero tener noticias tuyas de vez en cuando.
Un abrazo desde Santiago de Chile.
Hola Gabriel, muchas gracias por escribir y me alegro que te esté gustando! Saludos a Chile, de un argentino en España Seguimos en contacto
Seguimos en contacto
Hola Juan Ignacio, tu blog es simplemente fenomenal, me ayudo mucho en mi aprendizaje de machine learning. soy de formación ingeniero de organización industrial, cubano en brasil, pero estoy reinventandome y haciendo algunas cosas en machine leraning. tu blog me sirvion de mucho! Obrigado!!!!!
Hola Alejandro, me alegro mucho que estés reinventandote!, de eso se trata la vida (creo… con margen de error). Un saludo grande y espero que sigas bien!
Hola Juan Ignacio,
Excelente articulo como siempre, tu pagina web me esta ayudando mucho a aprender Machine Learning.
Tengo una pregunta con respecto al modelo. Al introducir los datos de un cliente solvente [6100,33463,2,5,10000] con buenos ingresos, buenos ahorros y poca cantidad a financiar el algoritmo me recomienda alquilar. La verdad que el perfil del cliente no se parece demasiado al de los datos de entrenamiento por lo que podria estar ahi el fallo. Me gustaria conocer tu opinion acerca del resultado y como podriamos mejorarlo.
Un saludo,
Hector
Hola Juan Ignacio, muchas gracias por estos artículos. Apenas empecé en este mundo de la inteligencia artificial este año y me está encantando. Estoy reforzando mucho los temas que estoy viendo con tus ejercicios.
Te hago una pregunta, cuando doy mi correo para recibir los artículos quincenales, en el correo no me deja dar clic a la suscripción. Quisiera saber si ya estoy en tus bases de datos para recibir los correos.
Muchas gracias
Muchas gracias por el artículo!
Una pregunta, ¿es indiferente que las variables sean categóricas o numéricas?
Has convertido en numérico el estado civil. Sí la forma de convertirlo en numérico hubiese sido otra (ej: casado=8, soltero=23..) ¿el resultado habría sido el mismo?
Repito: muchas gracias por el artículo
XXX
En este caso que son sólo 3valores, puede que no afecte demasiado, pero en general la transformación de categóricos a numéricos es sumamente importante y sí que influye el valor que se le asigne. Por eso surgen técnicas como one-hot encoder, TargetEncoder ó binning.
Saludos y gracias
muy bueno, me estoy leyendo todo el blog, y la verdad, aunque me guste leer en ingles, al no ser nativo en ese idioma, poder aprender con estos blog en español me ha ayudado mucho a entender, la unica recomendacion, como usuario que entra todos los dias a tu blog, es que coloque la caja de comentarios al principio y no al final de los comentarios, es mas para una mejor experiencia de usuario, saludos desde Argentina.
Hola, muchas gracias por leer el blog y por tu comentario!
Un saludo!